图像生成模型
回顾文字生成的两种方法
在文字生成模型中根据模型的输入是否与前一时刻的输出有关可以分为自回归AR模型与非自回归NAR模型两种,这两种生成方式的利与弊在图像生成中仍然存在。
自回归方法(AR)
Transformer-based的文字生成模型有很多,如GPT模型,大多使用自回归(Autoregressive, abbr. AR)的方法逐token生成。
ARM(Autoregressive Model,自回归模型)是一类用于建模时间序列数据的统计模型,其中当前时刻的观测值被认为是过去时刻观测值的线性组合,加上一个随机误差项。这类模型的核心思想是,当前时刻的数据依赖于先前时刻的数据。
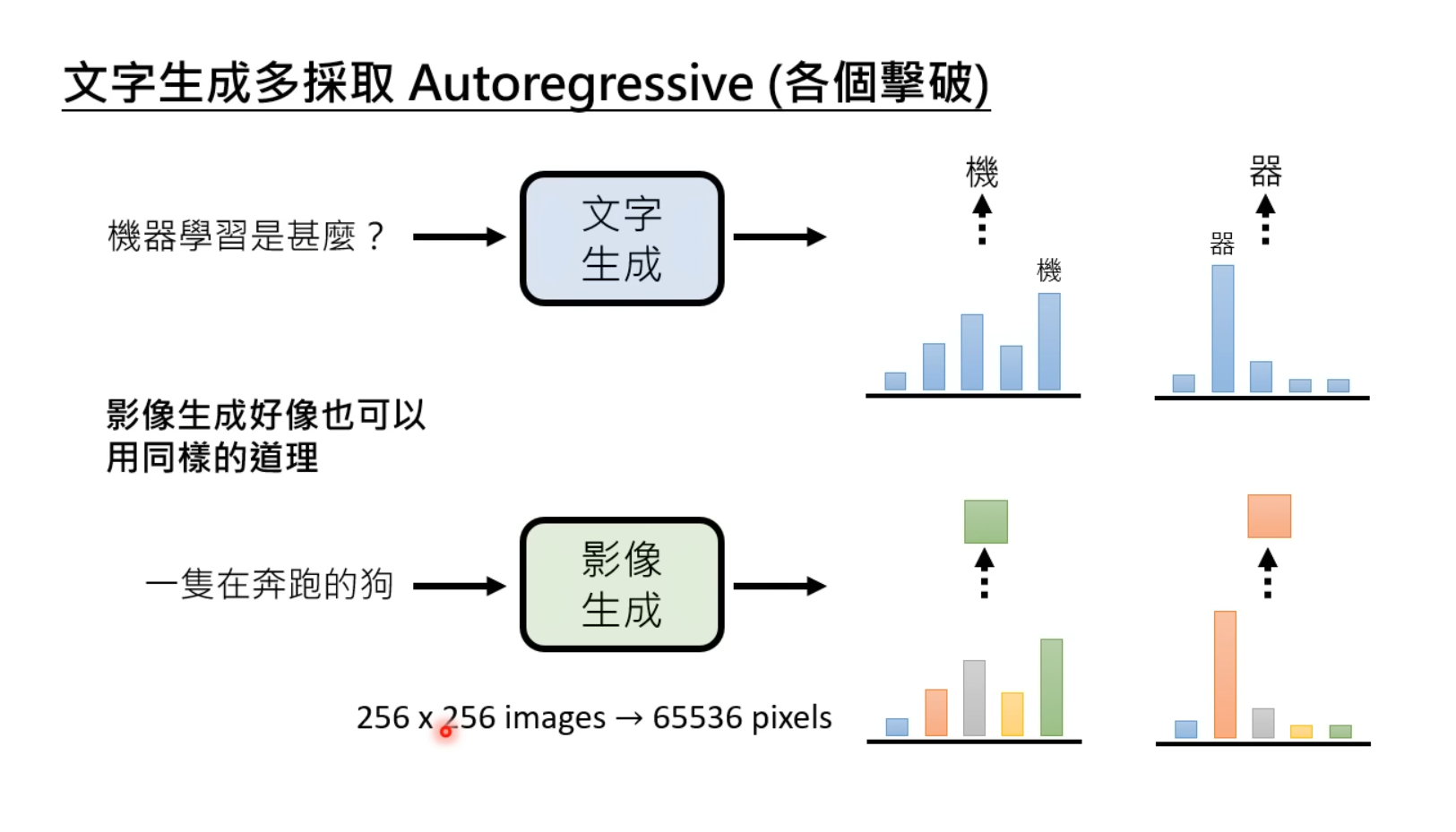
若把文字生成的AR方法对应到图像生成中的使用,即一个一个像素生成图像。由于当前对高清图像像素的需求越来越高,自回归的生成方式导致速度非常缓慢,但优点是后面生成的每一个像素都考虑了之前的所有像素,从而使生成的图像更清晰、更细腻、更加符合预期。
非自回归方法(NAR)
若使用NAR非自回归的方法一次生成所有像素,各像素在生成时无法考虑之间的语义信息,生成的图像质量普遍低于自回归方法生成的图像。
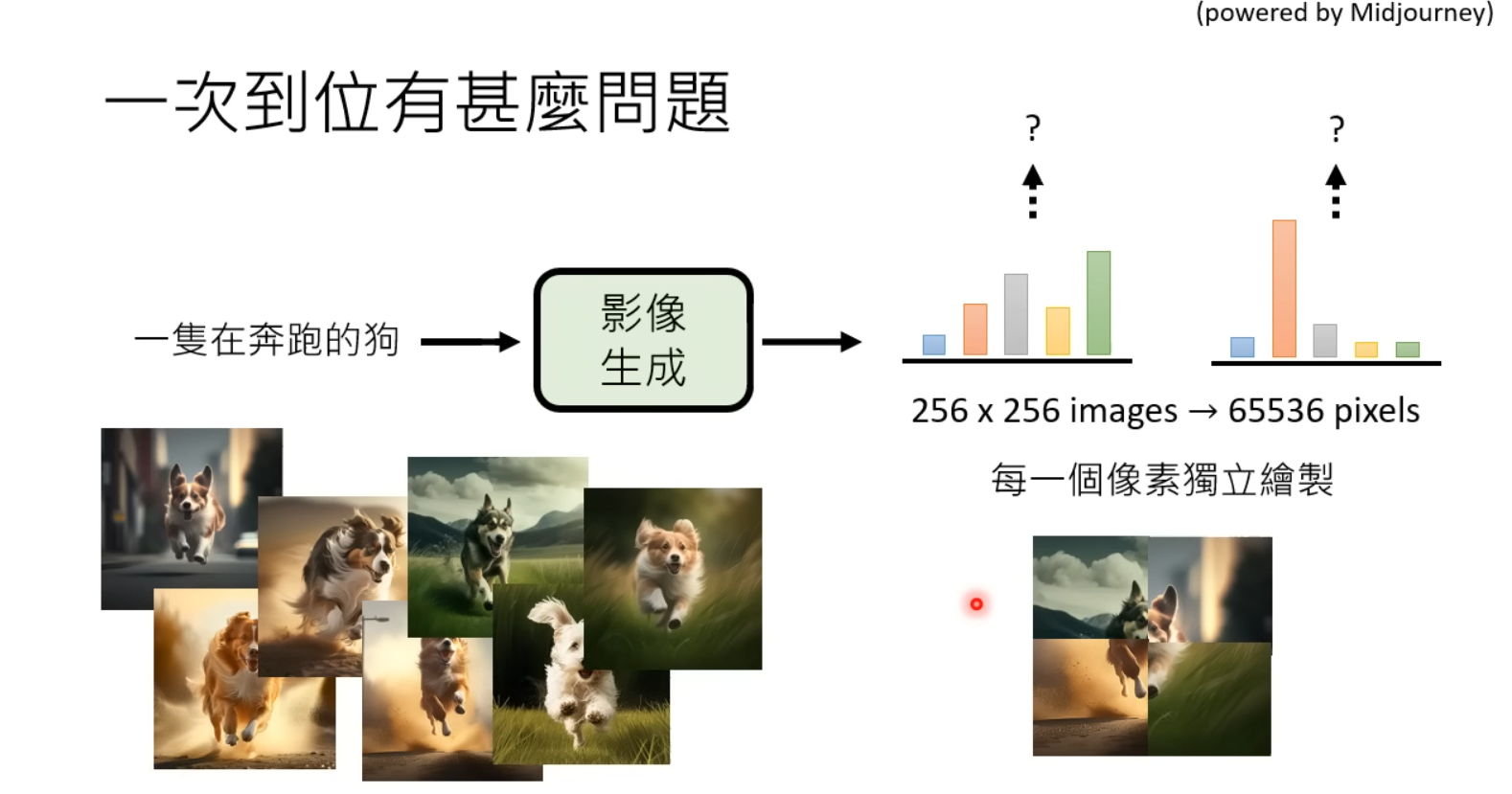
目前图像生成模型的共同点
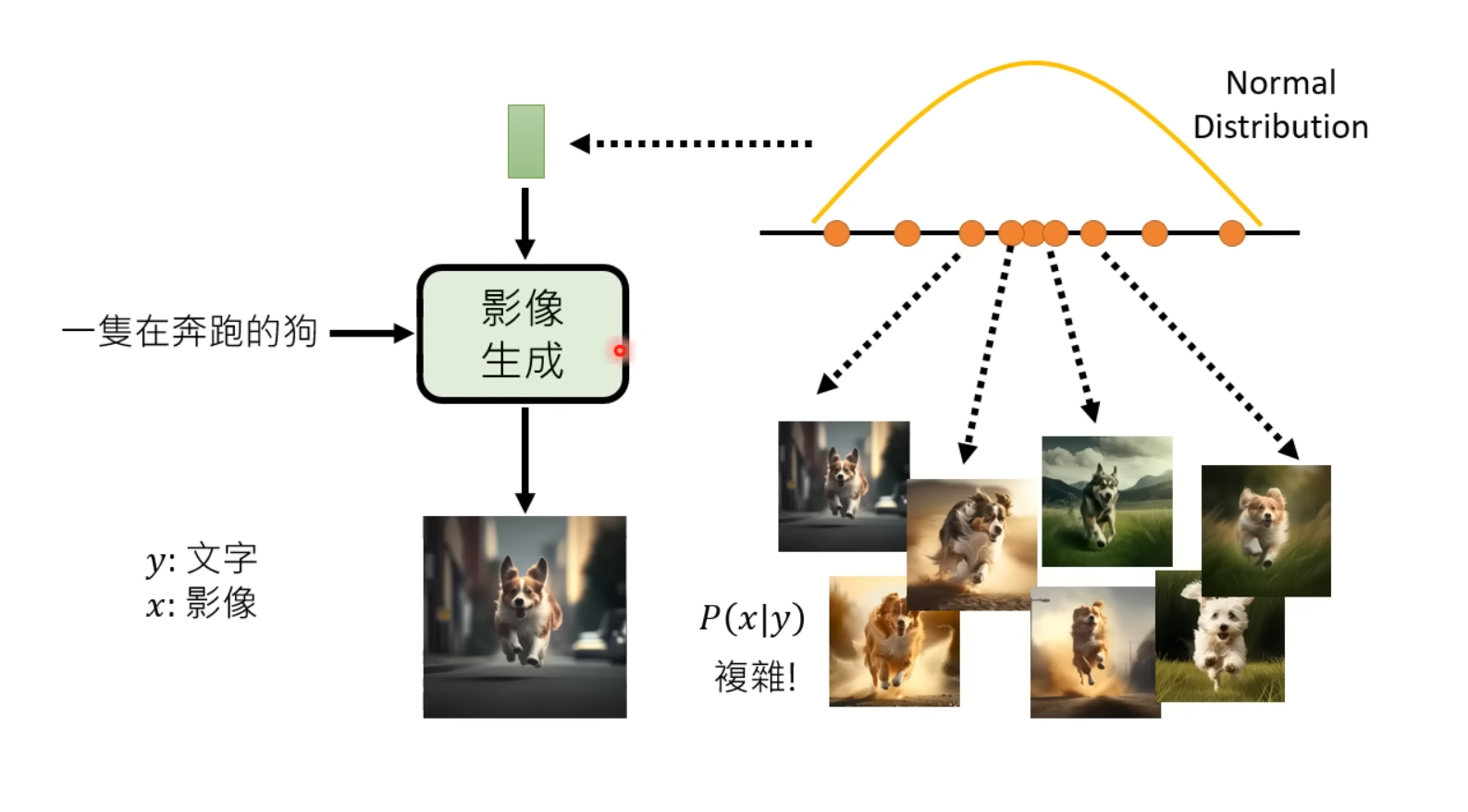
VAE、GAN以及Diffusion Model等生成模型,都不只是单独使用文字作为输入来生成图像,而是使用了从已知的随机分布(e.g. Normal Distribution)中sample出向量作为模型额外输入的方法。
大致的思想如下图所示,由于期待生成的图像并不是固定的,可以将预期输出看作是一个分布,即��,而图像生成模型需要完成的任务就是将输入的从某一随机分布中sample出的向量对应到图像预期输出分布中的某一个图像。
总结:由于根据文字prompt期待生成的图像并不是固定的,可以认为生成的图片在目标域(Target Domain)符合某种分布。因此目前的SOTA模型除了将文字Prompt作为输入,还从某随机分布中sample出图片shape的随机向量(矩阵)作为输入,期待模型根据prompt将源域(Source Domain)输入的随机向量映射到目标域的分布,生成对应的图片。
生成模型的共同结构
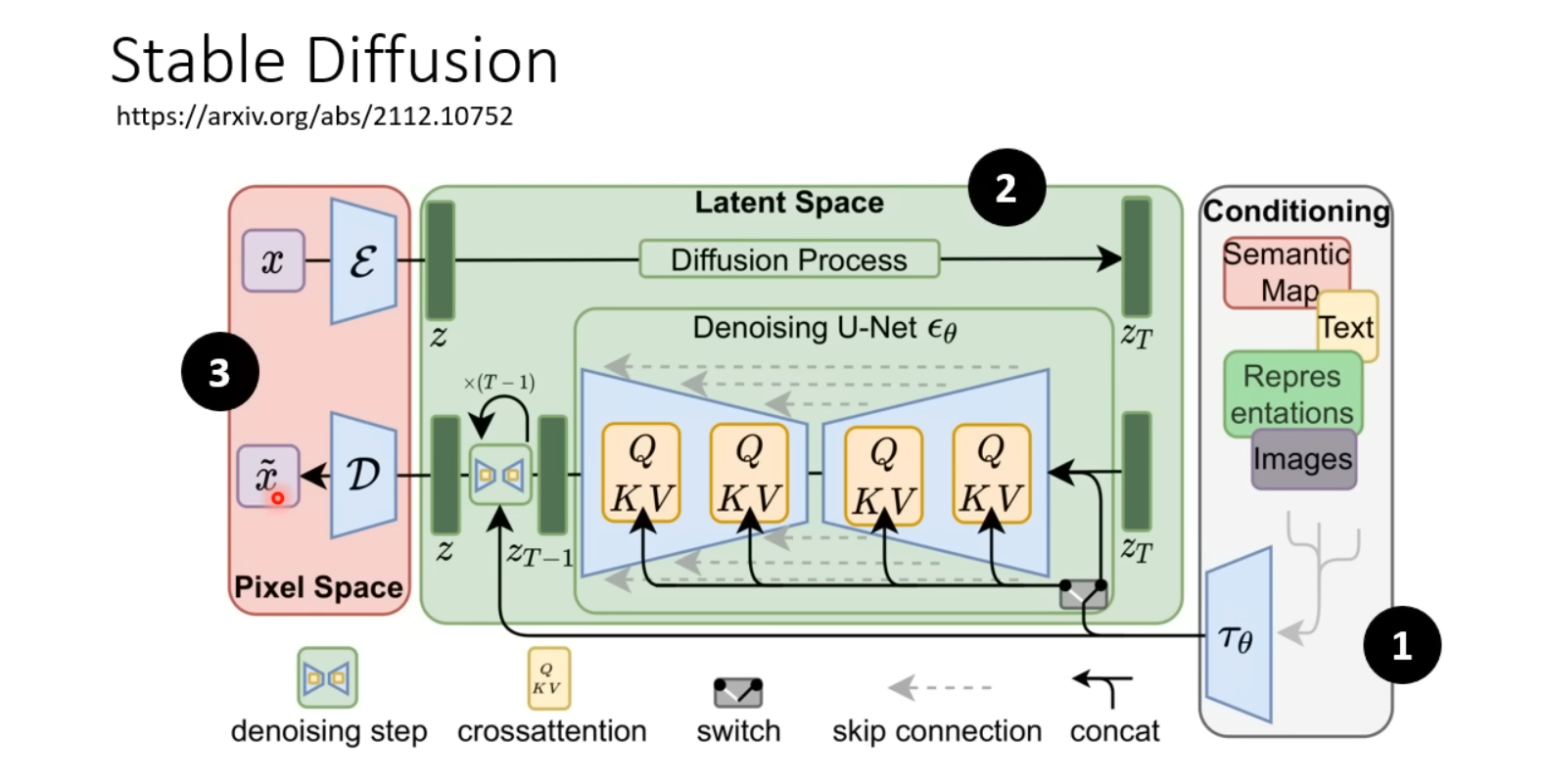
Stable Diffusion是目前图像生成的SOTA模型之一,在本章中我们快速的了解一下Stable Diffusion的大致框架以及原理。
通用框架概览
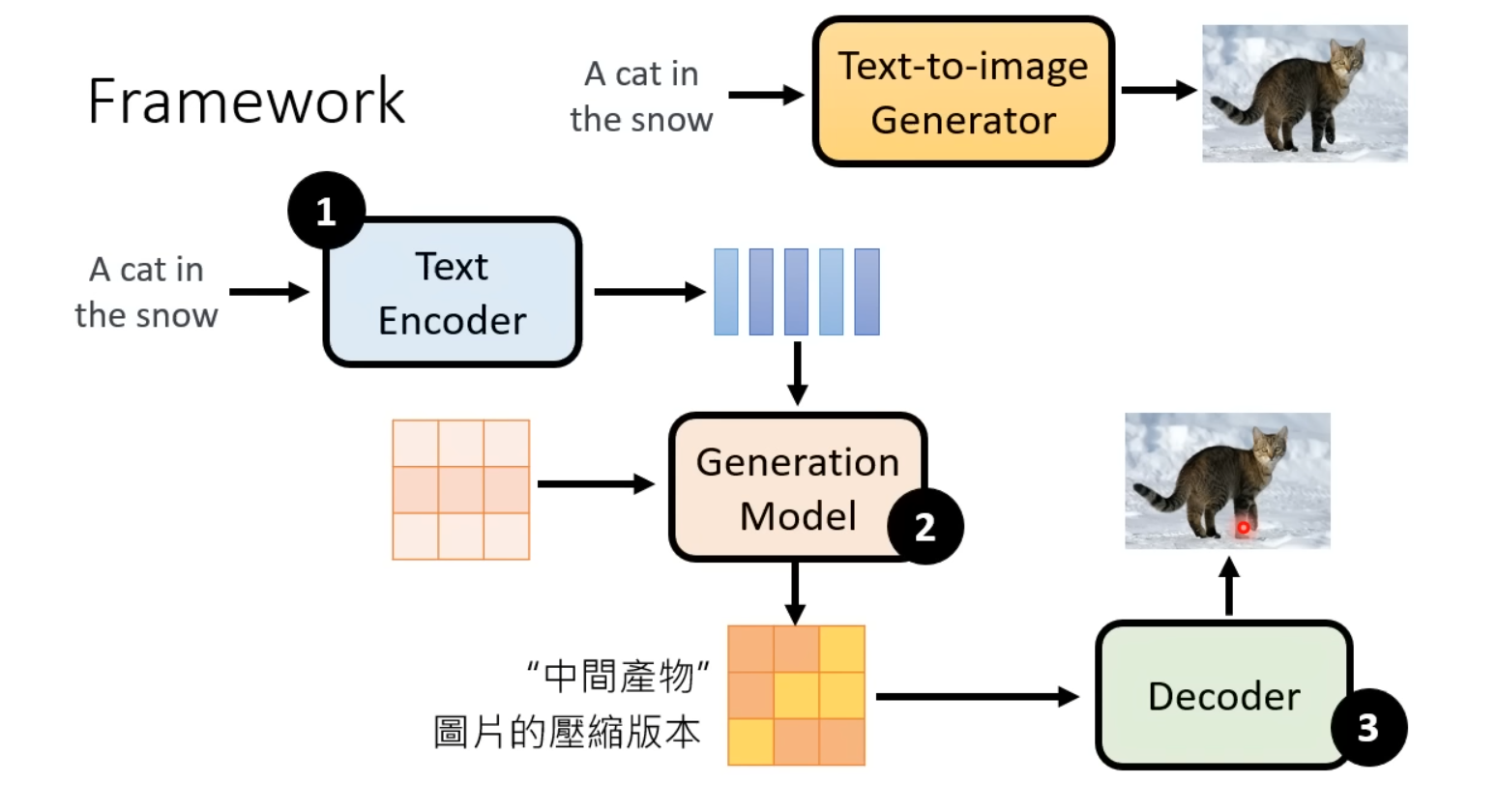
目前,如Stable Diffusion等SOTA图像生成模型都具备以下所示��的三个模块,通常情况下这三个模块分开训练,最终通过特殊的逻辑和规则组合在一起。
- Text Encoder:根据输入的text prompt进行嵌入表示
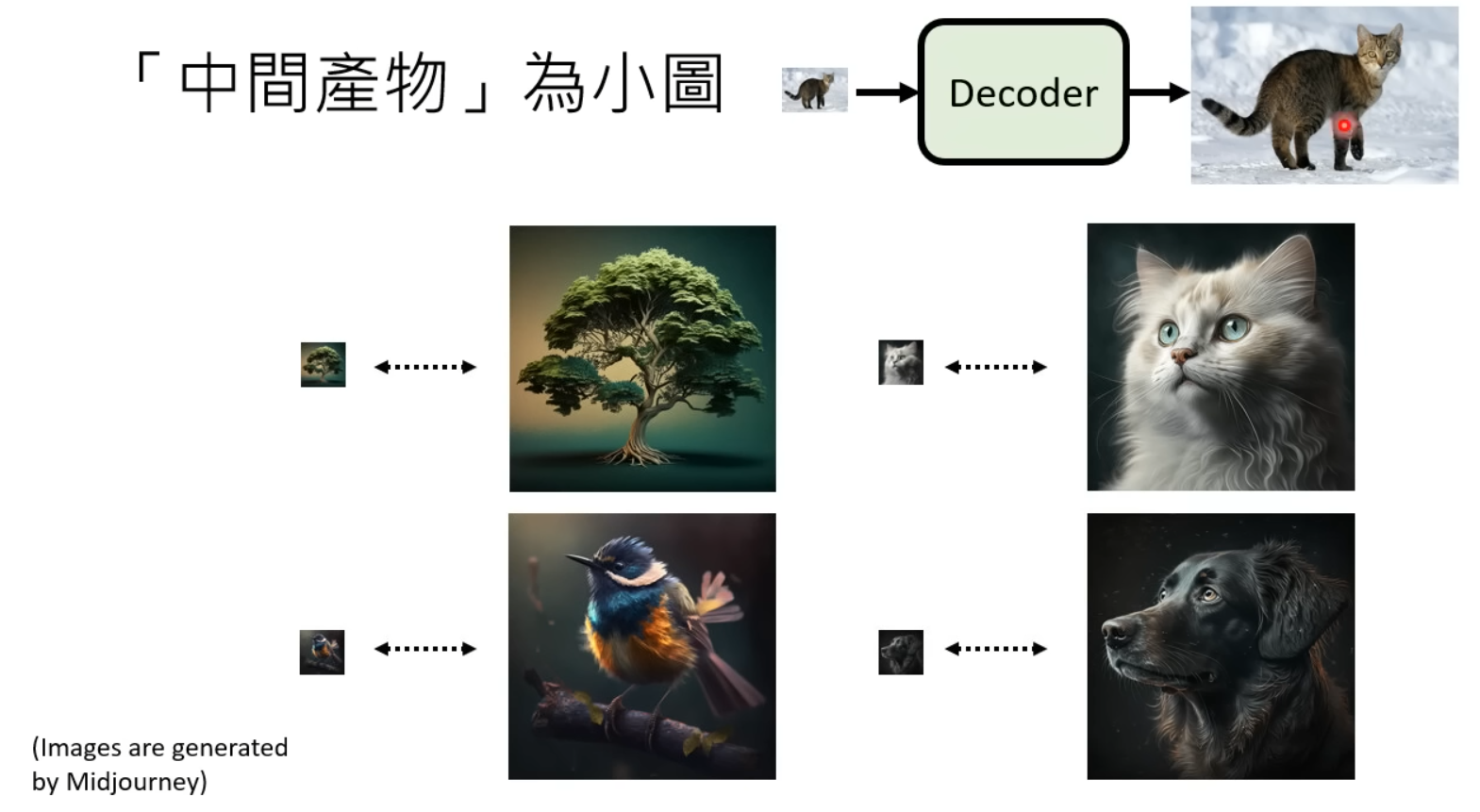
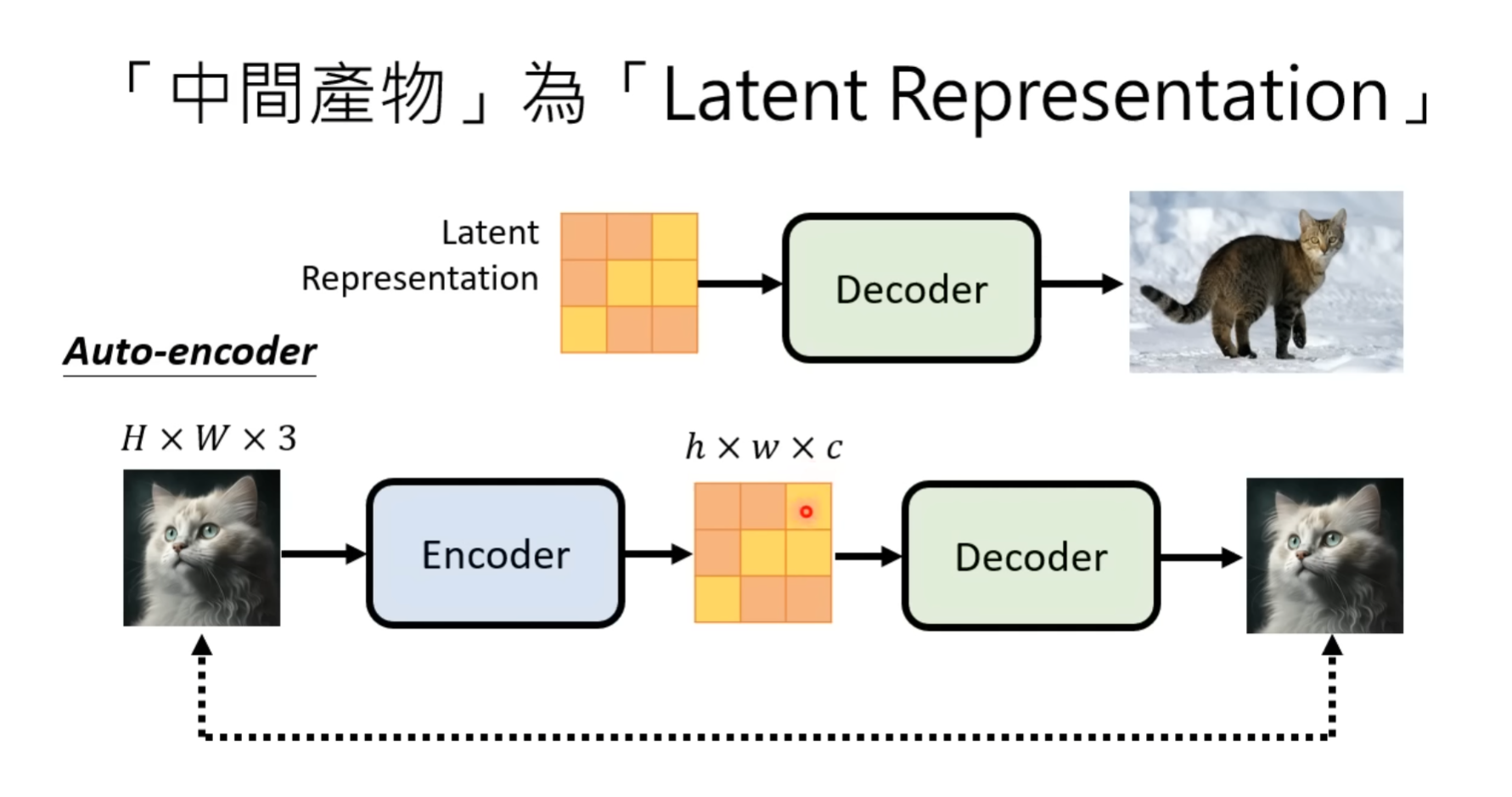
- Generation Model:接受Text Encoder输出的prompt表示以及从随机分布sample出的图像大小的向量,得到“中间产物”,中间产物有以下两种情况:
- 具有视觉意义但经过压缩比较模糊的图像
- 不具备视觉特征的矩阵(Latent Representation)
- Decoder:以上述的“中间产物”作为输入,生成出高清图像
通用框架的三个组成部分如下图所示:
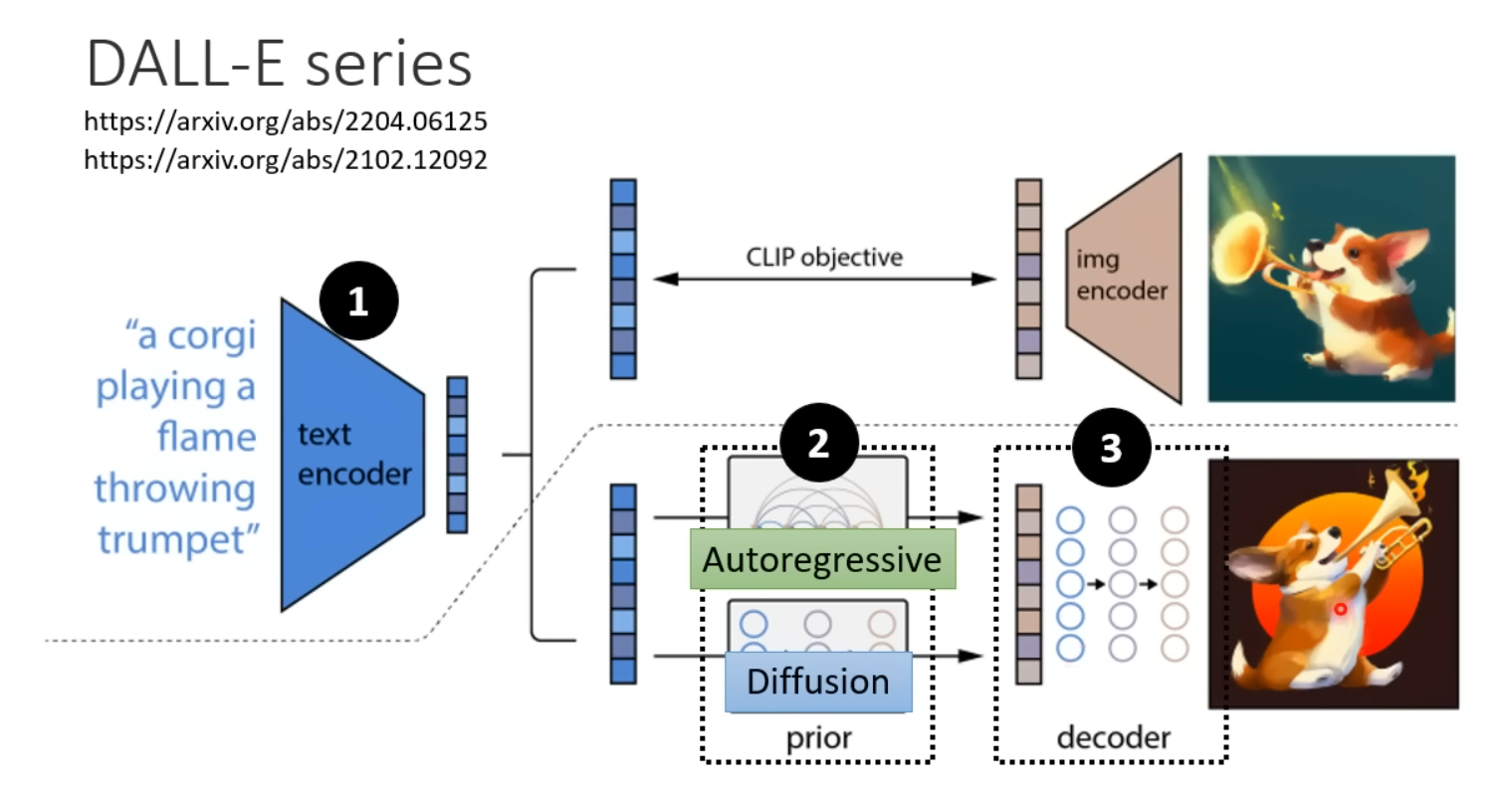
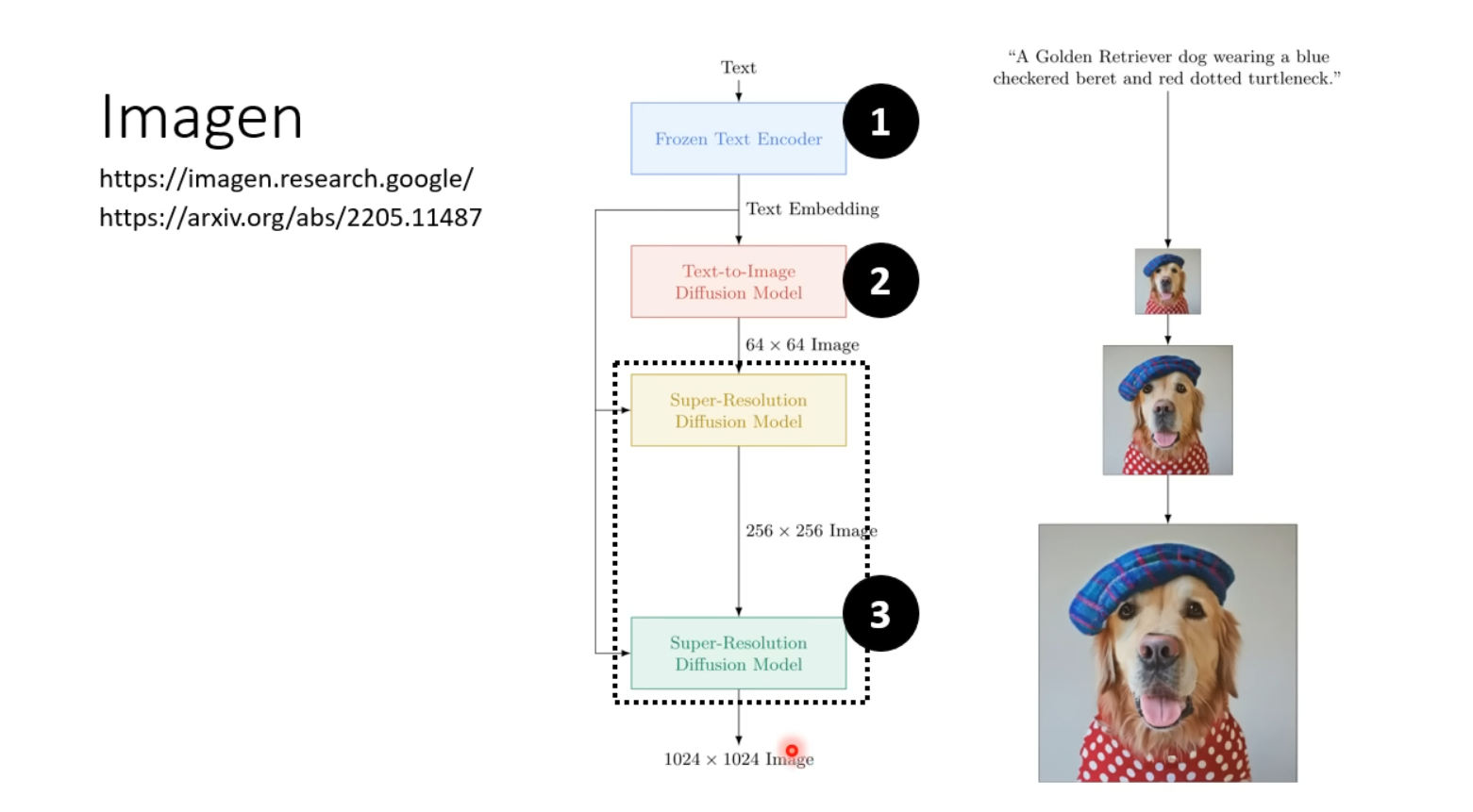
再附上Stable Diffusion、DALL-E系列以及Google的Imagen的结构说明。
其中Imagen将压缩版本的图片作为Generation Model的中间产物,Stable Diffusion以及DALL-E将Latent Representation作为中间产物。
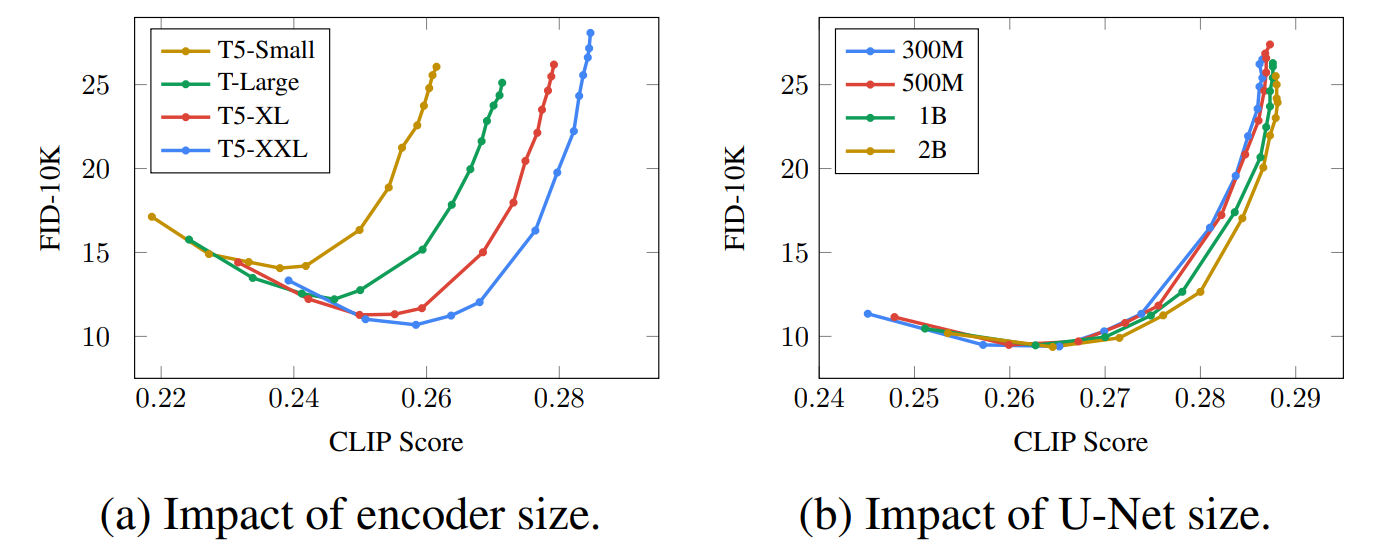
根据Imagen的实验结果,相对于Decoder即Diffusion Model的模型大小,Text Encoder的模型大小对图像生成模型的影响是非常大的。Text Encoder可以帮助模型理解prompt中在训练资料的文字-图像对中没有出现的新的词汇,从而提高图像生成的表现。
Scaling text encoder size is more important than U-Net size. While scaling the size of the diffusion model U-Net improves sample quality, we found scaling the text encoder size to be significantly more impactful than the U-Net size.
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Benchmark
下面介绍两种用于评估图像生成模型的常用Benchmark:FID与CLIP Score。
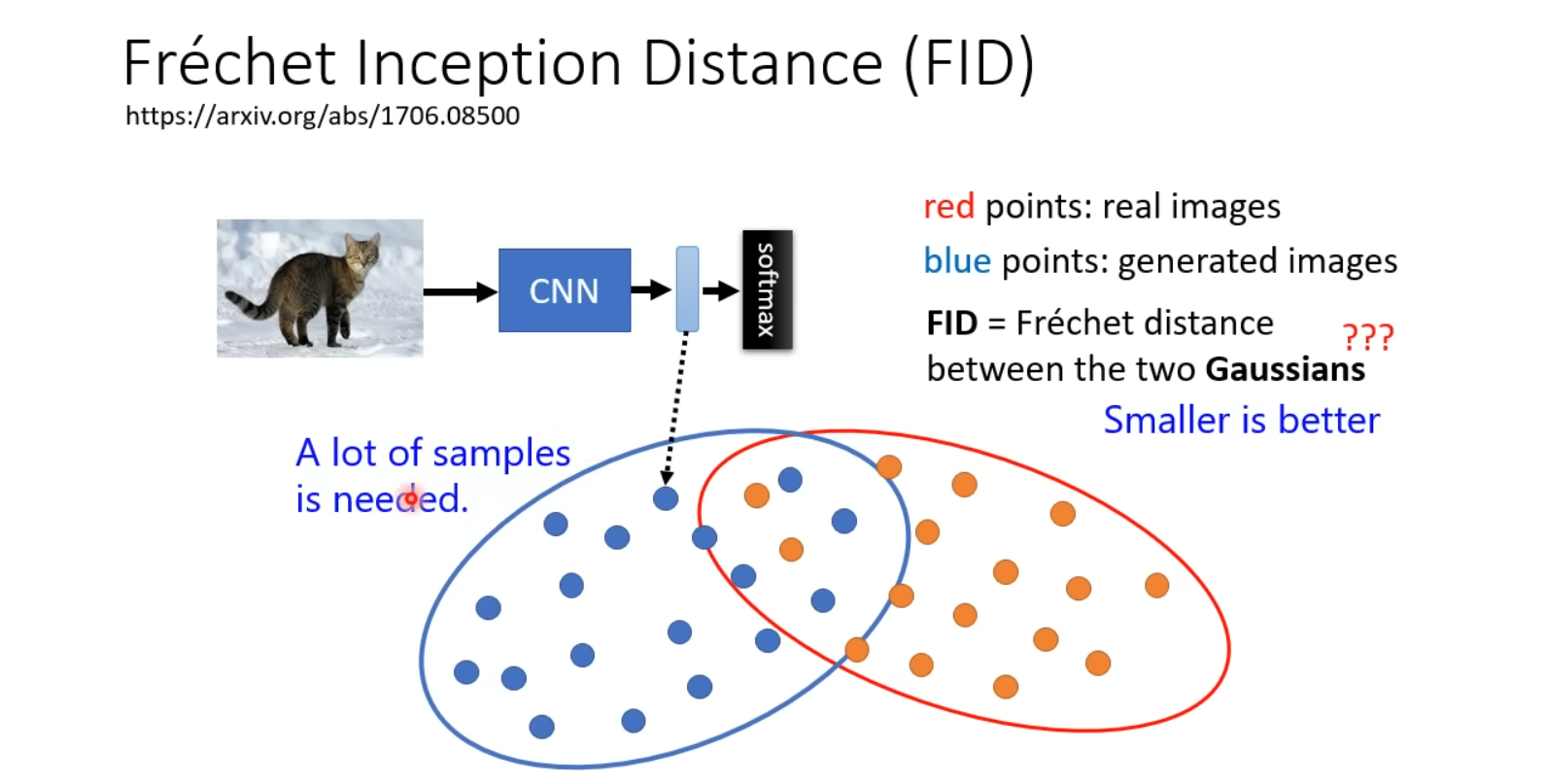
FID(Fréchet Inception Distance)
FID提供一个Pre-trained的CNN,该CNN通常使用预训练的Inception v3模型。在计算FID时,生成图像和真实图像分别输入到预训练的CNN中,提取出各自的特征表示向量(Representation)。这两个Representation越接近,代表输出的图像越像预期的“真实”图片。
在FID中,做出了如下重要的假设**:将生成的图像真实的图像经过CNN输出的Representation看作是sample自两个高斯分布的随机变量**。然后,通过计算两个特征向量的均值和协方差矩阵来得到两个高斯分布的参数。最后,利用两个高斯分布之间的Fréchet距离来衡量生成图像与真实图像之间的差异。
其中,和分别是第一个和第二个高斯分布的均值向量;和则是它们的协方差矩阵;表示矩阵的迹运算。
高斯分布的均值向量从观测到的数据中计算出来的。对于一个-维高斯分布,其均值向量可以表示为一个长度为的列向量,其中的每一个元素都是一个特定维度的平均数,这可以通过在每个维度上进行简单的算术平均来完成。
值得注意的是,FID指标需要一定数量的生成图像和真实图像来进行统计估计�。这是因为FID的计算是基于两个高斯分布之间的距离计算的,因此需要足够多的样本数量才能够获得较为准确的概率分布估计。
CLIP Score
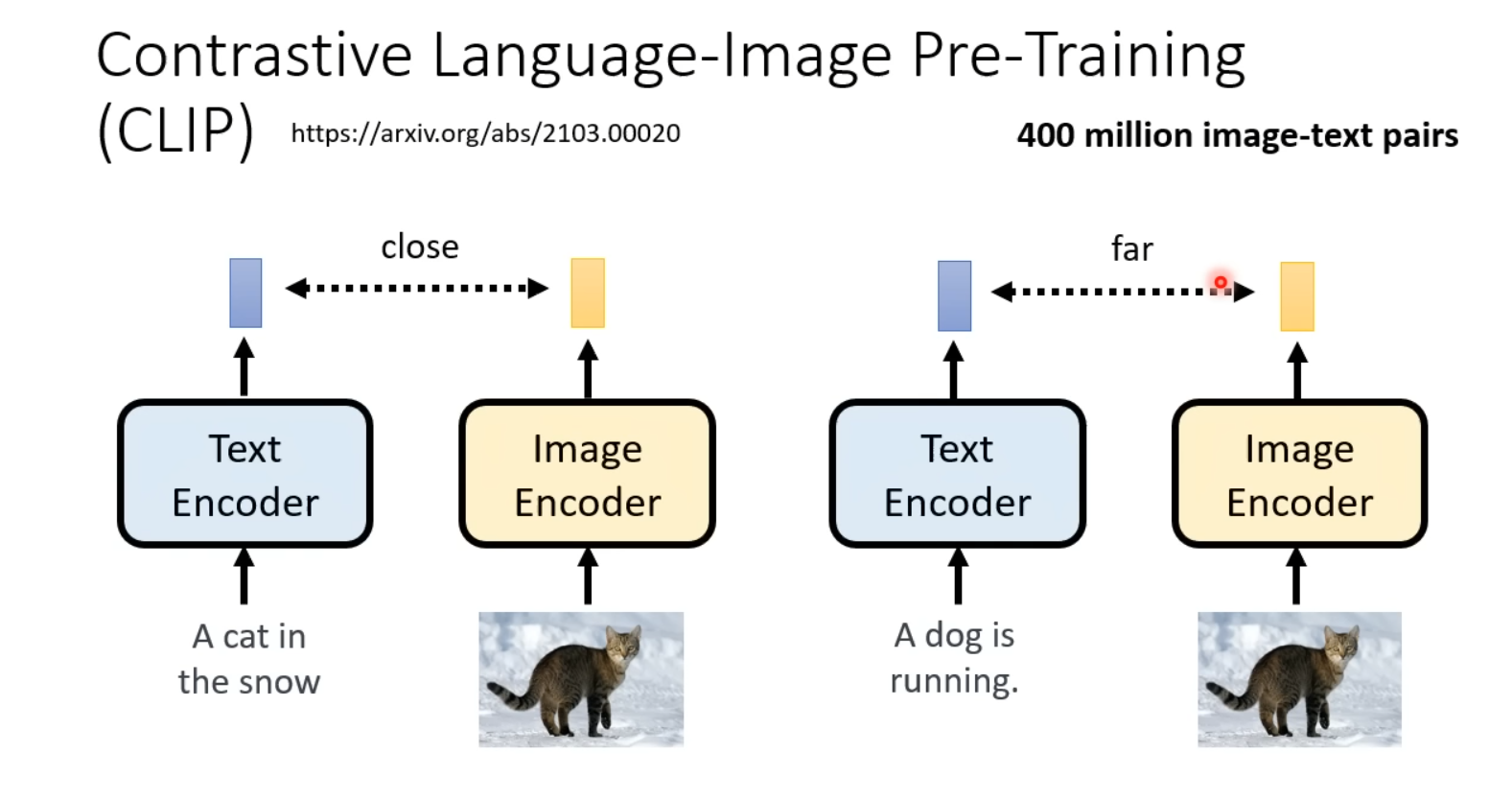
CLIP Score中的CLIP指的就是OpenAI的CLIP(Contrastive Language-Image Pre-Training)模型。
具体来说,CLIP Score的计算方式是将用于生成图像的文字prompt输入至CLIP的Text Encoder中得到一个Representation,再将对应prompt生成的图像输入至CLIP的Image Encoder中得到对应的Representation,计算二者之间的距离,即得到CLIP Score。分数越小,代表文字和图像更align。
通用框架解析
Generation Model
Generation Model的生成过程其实就是Denoise的过程。具体来讲,输入文字Prompt以及从随机分布中sample出的与预期生成图像具有相同大小的噪声矩阵,预测出输入图片中的噪声分布,在输入�图像中减去噪声,输出去噪后的图像。Generation Model的最终输出是中间产物,这个中间产物可以是图像的压缩版本,也可以是一个Latent Representation。因此,训练Generation Model其实就是训练一个Noise Predictor。
中间产物是压缩图像
当Generation Model的中间产物是压缩图像时,如Diffusion模型,在训练Generation Model时的训练资料可以通过对数据集中的原始图片添加与图像大小一致地从已知随机分布中sample出的噪声来获得。此时加入噪声后的图像可以作为压缩图像输入至Noise Predictor中,而需要预测出的噪声分布的Ground Truth就是sample出的噪声。
中间产物是Latent Representation
中间产物是Latent Representation时,同样采取从已知随机分布中sample出噪声再添加到网络的输入作为生成Ground Truth的策略,但是还额外需要一个Encoder来产生Latent Representation。
这里的Encoder使用数据集中的图片(即期待模型最终输出的图片)作为输入,输出该图片的某种Latent Representation,经过从随机分布中sample出的噪声的加入,输入至Noise Predictor中。从随机分布中sample出的噪声就是Noise Predictor的Ground Truth。
Decoder�
Generation Model的训练需要大量成对的(Pair)文字-图像资料。而对于Decoder来说,它的输入是中间产物(即Generation Model生成的压缩的图片或Latent Representation),输出的是还原出的高分辨率的图像,它的训练是不需要额外pair的文字-图像资料。
中间产物是压缩图像
当Generation Model的输出是压缩版本的图像时,Decoder的训练资料可以将从互联网上fetch到的图像作为label,并对这些图像做Down Sampling来获得压缩版本的图像作为Decoder训练时的输出。
中间产物是Latent Representation
当中间产物是Latent Representation时,需要训练一个Auto-Encoder,使用Encoder-Decoder的结构训练生成模型的Decoder。
具体来讲,向Encoder中输入数据集中的高清预期图片,Encoder将其转换为某种Latent Representation,Decoder再吃Encoder的输出,最终输出还原出的高清label图片,训练的方向是让输出的图片与输入的图片越接近越好。在这个过程中,不需要额外的标注,Auto-Encoder和生成模型的Decoder一起更新参数。
常见图像生成模型速览
在这个模块大致介绍目前常见的几种图像生成模型,其中Diffusion Model以及GAN将在以后的文章中详细讲解。
变分自编码器(VAE)
变分自编码器(Variational Auto-Encoder, abbr. VAE)的训练策略是使用Encoder将输入图像对应(嵌入)到一个符合某随机分布的向量,再将该向量作为Decoder的输入,加上文字prompt后,期待模型产生合适的图像。
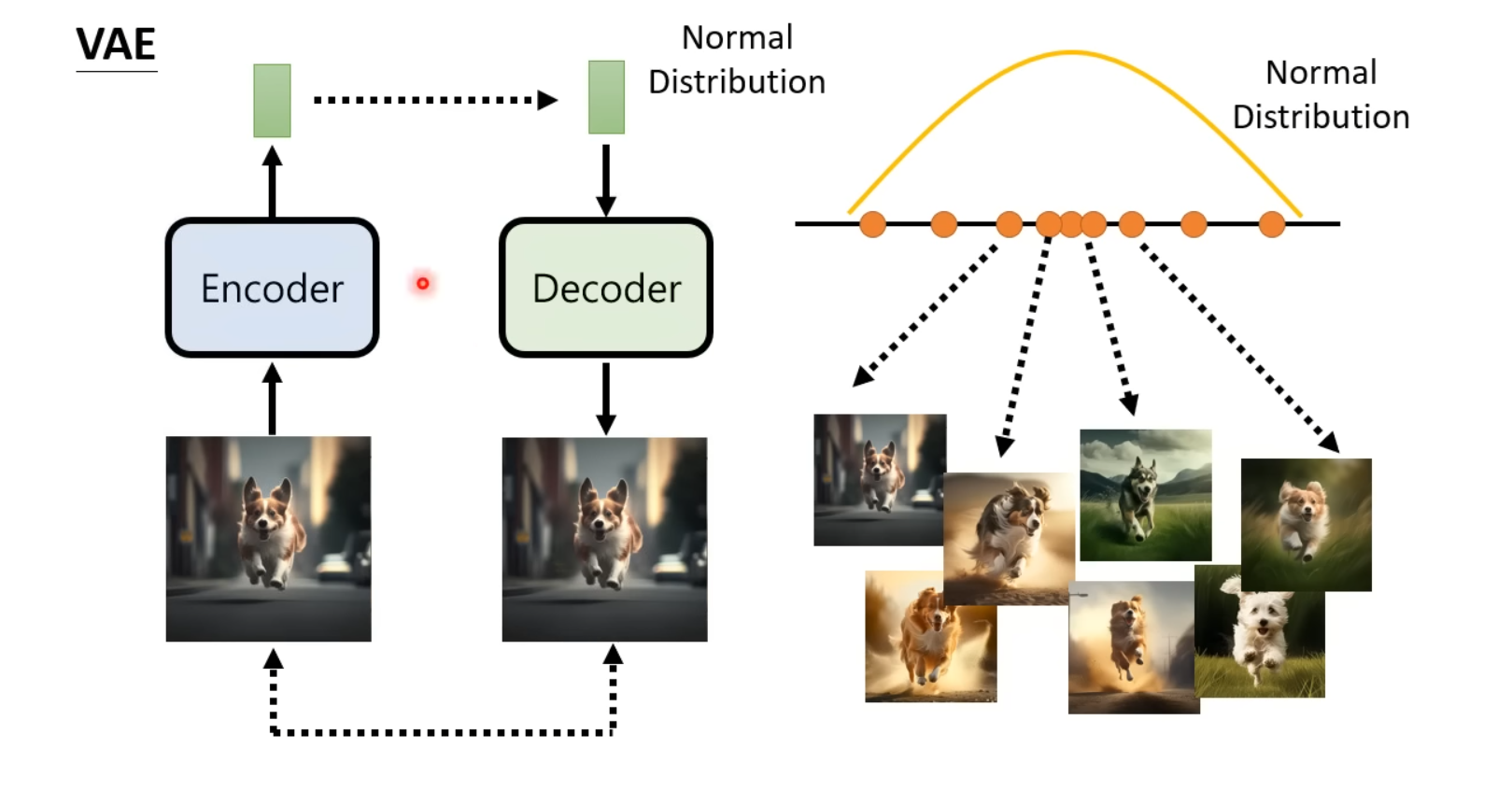
VAE在训练过程中,期待Ecoder输入多张图片后,输出的向量在一起符合某个随机分布(e.g. Normal Distribution),并不是Encoder直接输出一个Distrubution。
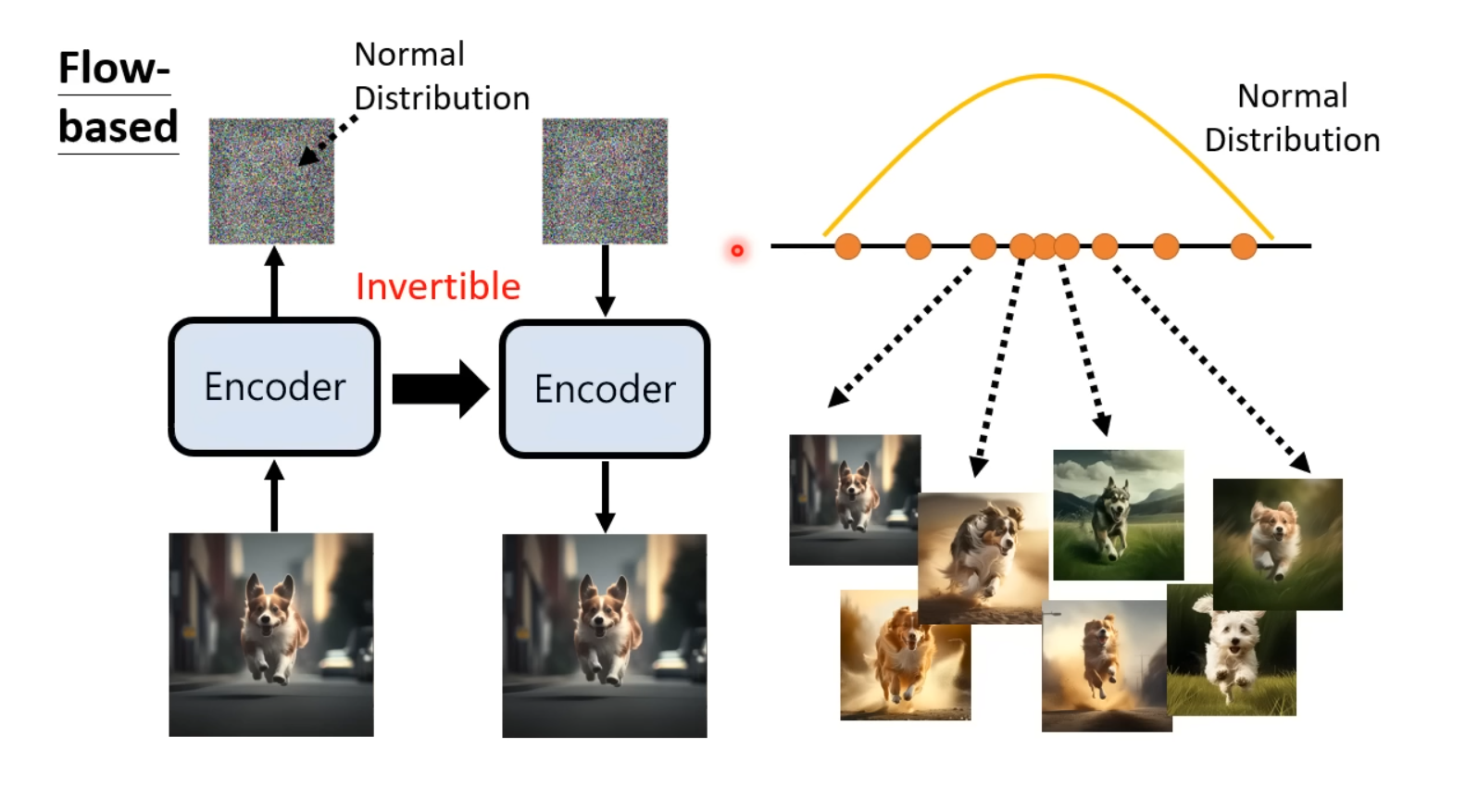
基于流的生成模型(Flow-Based Generative Model)
基于流的生成模型采用特殊的网络结构的设计,将Encoder设计为可逆的(invertible),在训练阶段喂入多张图片,期待模型的向量符合某个随机分布。而在预测阶段,由于Encoder是可逆的,输入从该随机分布中sample出来的向量,期待输出对应的图像。
注意,由于Encoder是可逆的,在训练阶段其输入的图片矩阵的形状应该等于输出的随机分布向量的形状,在推理阶段亦然。
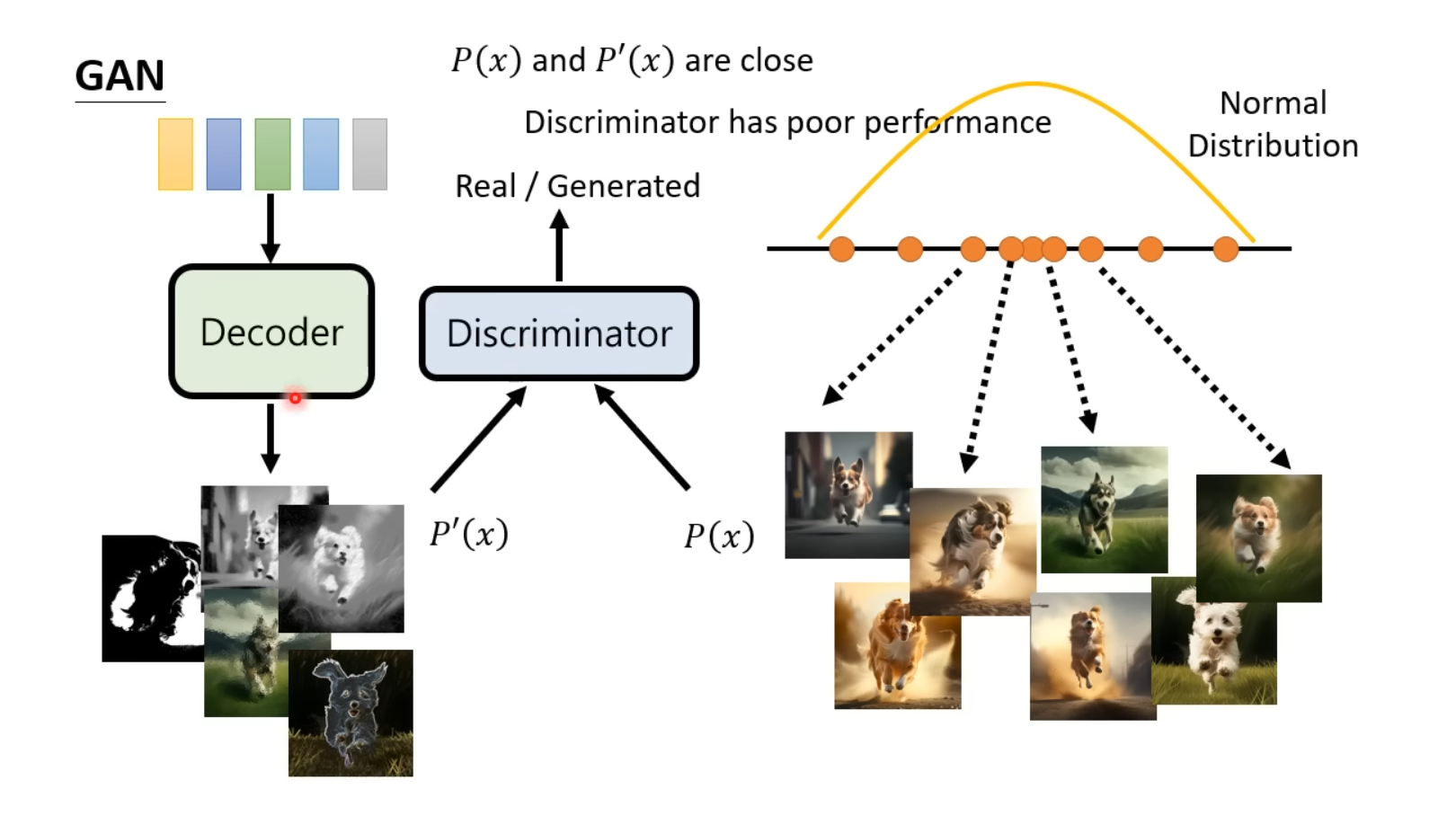
生成对抗网络(GAN)
GAN模型的结构分为Generator和Discriminator,其中Generator接受来自随机分布的向量,产生预期图像;Discriminator接受生成器输出的图像或真实图像,输出输入的图像是真实图像的概率。在训练过程中,通过固定生成器参数来更新辨别器参数、固定辨别器参数更新生成器参数的往复交替训练来形成“两个网络对抗”�的效果,从而使得生成器生成的图像更逼真(与输入的真实图像更近似)、辨别器识别是否是输入的真实图像的精确度更高。
扩散模型(Diffusion Model)
扩散模型的核心思想是对输入的图片加入噪声使其成为从某一随机分布sample出的向量,并在这个过程中训练出Noise Predictor;在生成图片时,输入从该随机分布中sample出的向量,使用训练出的Noise Predictor对噪声denoise从而获得生成的图片。
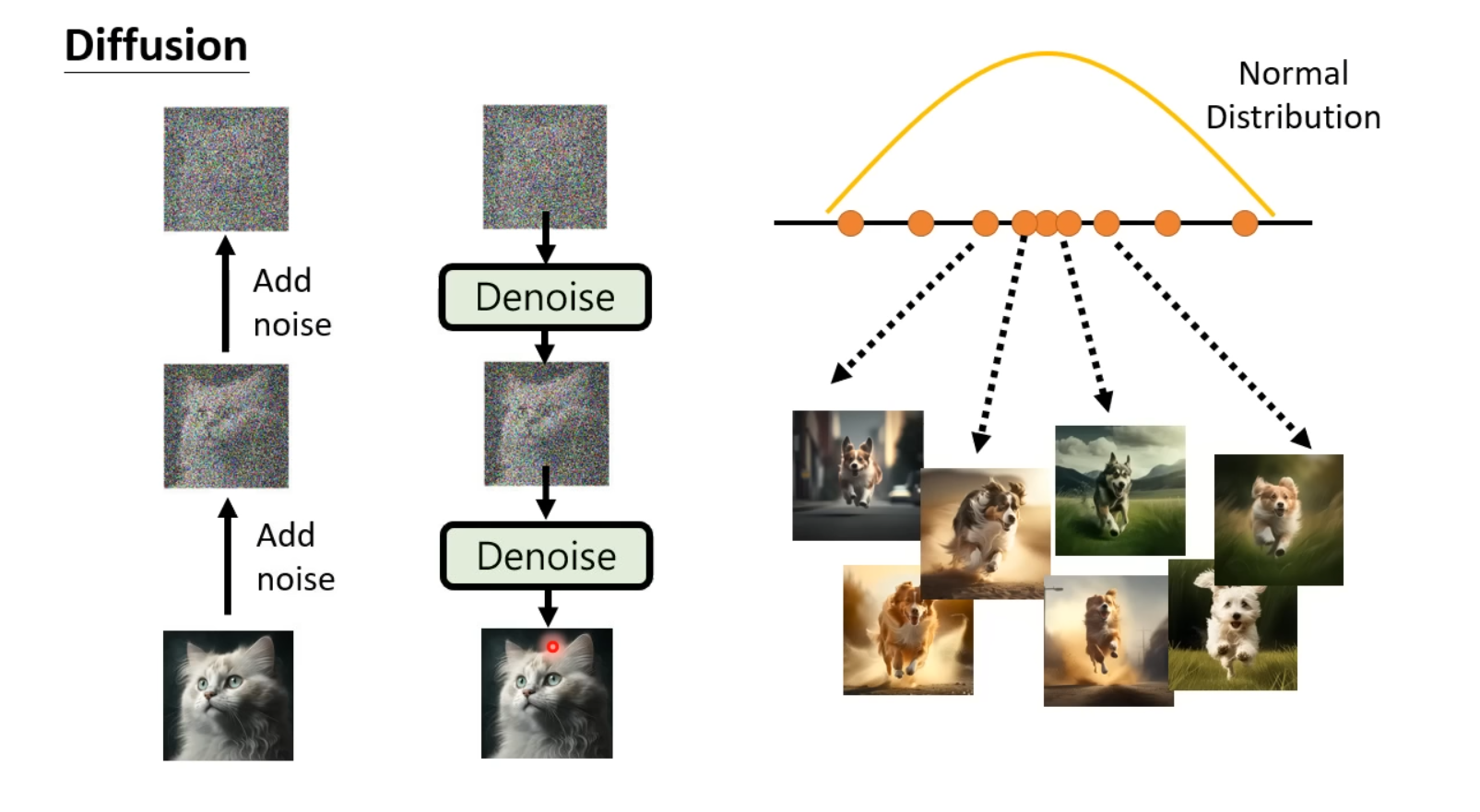
以DDPM(Denoising Diffusion Probabilistic Models)模型为例,模型在denoise时为每个denoise步骤赋予一个编号,越早进行denoise的步骤编号越大,因此,这个编号也代表着图像中噪声的严重程度。在Denoise模块中,模型根据输入的带有噪声的图片、文字prompt以及噪声的严重程度(即denoise的步骤)预测出该图片中噪声的分布,然后将输入的图片中减去预测出的噪声得到denoise后的图片。
Denoise模块的目标是预测出输入的噪声图片中的噪声,其资料可以通过对数据集中的图片不断加入从Gaussian Distribution中sample出的噪声的方法来获得,这个加噪声的过程我们称为Forward Process or Diffusion Process。此时将加入噪声后的图片、文字prompt以及denoise的步骤序号作为输入,sample出的噪声作为Ground Truth对noise predictor进行训练。