查漏补缺
这里记录着在学习过程中发现的理解或操作方面出现的错误,温故知新。
Python的广播机制��
-
进行广播的条件:两个矩阵的后缘维度相同或其中一方的维度为1。
- 后缘维度相同:A为(3,4,5)的三维数据,B为(4,5)的二维数组。由于A和B的后缘维度都为(4,5),所以可以进行广播。同理,当A为(3,4)的二维数组,B为(4,)的数组,他们的后缘维度都是4,所以可以进行广播。
- 后缘维度中有一方维度为1:A为(4,5)的二维数组,B为(4,1)的二维数组,其中一方维度为1,可以进行广播。
-
广播的原理:在运算过程中,Python逐步对数组进行广播,并不进行实际的复制操作,节省内存。
以下是举出具体例子进行分析:
import numpy as np
import torch
x = torch.tensor(np.arange(9), dtype=torch.float32)
x = torch.reshape(x, (3, 3))
print(x)
x1 = x[:, :, None] # (3, 3, 1)
print(x1)
"""
tensor([[[0.],
[1.],
[2.]],
[[3.],
[4.],
[5.]],
[[6.],
[7.],
[8.]]])
"""
x2 = x[:, None] # (3, 1, 3)
print(x2)
"""
tensor([[[0., 1., 2.]],
[[3., 4., 5.]],
[[6., 7., 8.]]])
"""
output = x1 + x2
print(output)
"""
tensor([[[ 0., 1., 2.],
[ 1., 2., 3.],
[ 2., 3., 4.]],
[[ 6., 7., 8.],
[ 7., 8., 9.],
[ 8., 9., 10.]],
[[12., 13., 14.],
[13., 14., 15.],
[14., 15., 16.]]])
"""由于x1与x2在第0维度上维度相同,所以Python可以直接进行逐元素相加,即依次进行如下运算
但在第0维度的相加过程中出现了shape为(3, 1)的矩阵与shape为(1, 3)的矩阵相加的情况,此时进行广播,将(3, 1)的每一列复制三次为(3, 3),将(1, 3)的每一行复制三次为(3, 3),再进行逐元素相加。
其实,上述的过程还可以再细分为,x1[0, 0, :]与x2[0, 0, :]相加时出现了第一次广播,将x1[0, 0, :]复制了三次与x2[0,0, :]�完成相加,这里不再赘述,最终想表达的原理是广播机制是在运算过程当中进行的,并非一次性将二者全部复制为对应的最小公倍数形状后再进行运算。
点积(dot product)与矩阵乘法(matmul product)
- 点积在Python中对应的运算符为*,进行矩阵之间的逐元素乘法。在点积运算中,运算矩阵二者形状不一样时可能涉及到广播机制;
- 矩阵乘法在Python中对应的运算符为@,进行常规矩阵乘法。遵守左矩阵的列数必须等于右矩阵的行数,且输出矩阵的行数等于左矩阵的行数、输出矩阵的列数等于右矩阵的列数的规则。
zip函数与解压操作*
当你有多个列表(或其他可迭代对象)时,zip函数可以将它们逐个配对成元组。而*操作符用于解压元组,将元组中的元素分别作为参数传递给函数。
以下是一个简单的例子:
# zip函数的例子
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
list3 = ['x', 'y', 'z']
# 使用zip将多个列表配对成元组
zipped_lists = zip(list1, list2, list3)
# 打印配对后的元组
for item in zipped_lists:
print(item)
输出:
(1, 'a', 'x')
(2, 'b', 'y')
(3, 'c', 'z')
在这个例子中,zip将list1、list2和list3中相同位置的元素组合成元组。
接下来,我们可以使用 * 操作符解压这些元组:
# *解压操作的例子
unzipped_lists = zip(*zipped_lists)
# 打印解压后的列表
for item in unzipped_lists:
print(item)
输出:
(1, 2, 3)
('a', 'b', 'c')
('x', 'y', 'z')
在这个例子中,*操作符将先前由zip组合的元组解压,分别放回原始的列表。
对batch_first参数的理解
对于不同的网络层,输入的维度虽然不同,但是通常输入的第一个维度都是batch_size,比如torch.nn.Linear的输入(batch_size,in_features),torch.nn.Conv2d的输入(batch_size, C, H, W)。
而RNN的输入是(seq_len, batch_size, input_size),batch_size位于第二维度!虽然可以将batch_size和序列长度seq_len对换位置,此时只需令batch_first=True。
但是为什么RNN输入默认不是batch first=True?这是为了便于并行计算。
因为cuDNN中RNN的API就是batch_size在第二维度。进一步讲,batch first意味着模型的输入(一个Tensor)在内存中存储时,先存储第一个sequence,再存储第二个,而如果是seq_len first,模型的输入在内存中,先存储每一个sequence的第一个元素,然后是第二个元素,两种区别如下图所示:
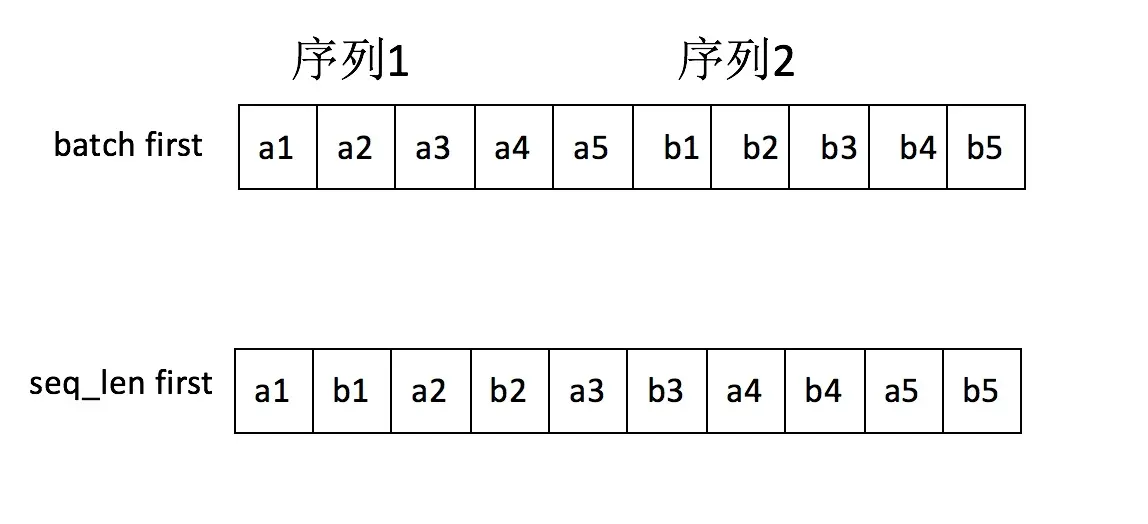
seq_len first意味着不同序列中同一个时刻对应的输入单元在内存中是毗邻的,这样才能做到真正的batch计算。