Movie Gen: A Cast of Media Foundation Models
主要功能展示
Meta Movie Gen 可以实现具有同步音频的视频生成、个性化角色的视频生成并支持视频编辑。
Movie Gen 实现的主要功能来自于提出的两个 foundation model,分别为 Movie Gen Video 以及 Movie Gen Audio。
- Movie Gen Video:30B 参数的大模型,支持 T2I 以及 T2V 的联合生成,最高可根据输入的文本提示生成 16 秒的 1080P HD 视频。
- Movie Gen Audio:13B 参数的大模型,支持 V2A 以及 T2A,最高可根据输入的视频以及文本提示生成 48kHz 的高质量同步音频。
Text-to-Video 视频生成
个性化视频
视频精确编辑
音频生成
Movie Gen Video
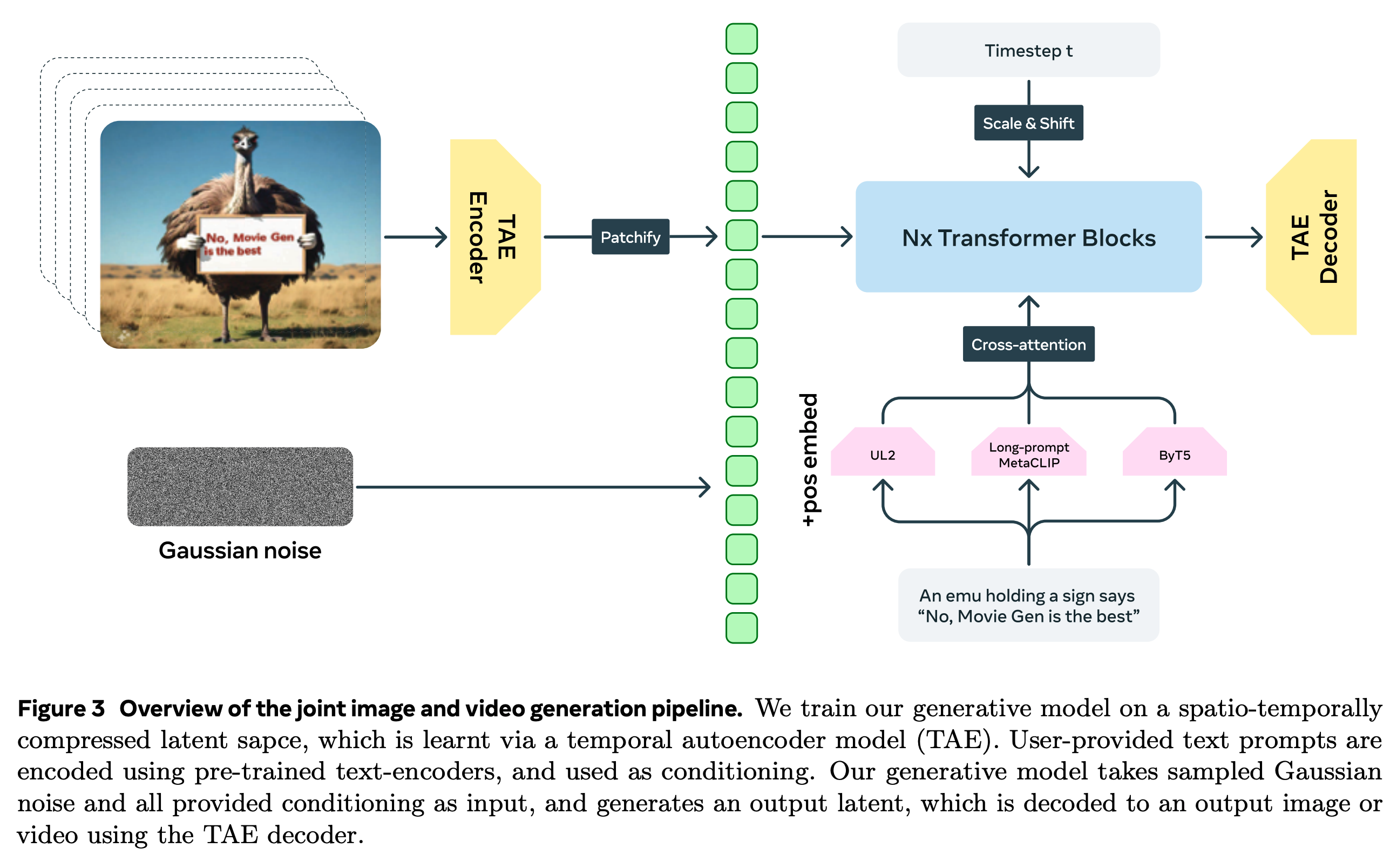
Joint Image and Video Generation(图像视频联合生成)
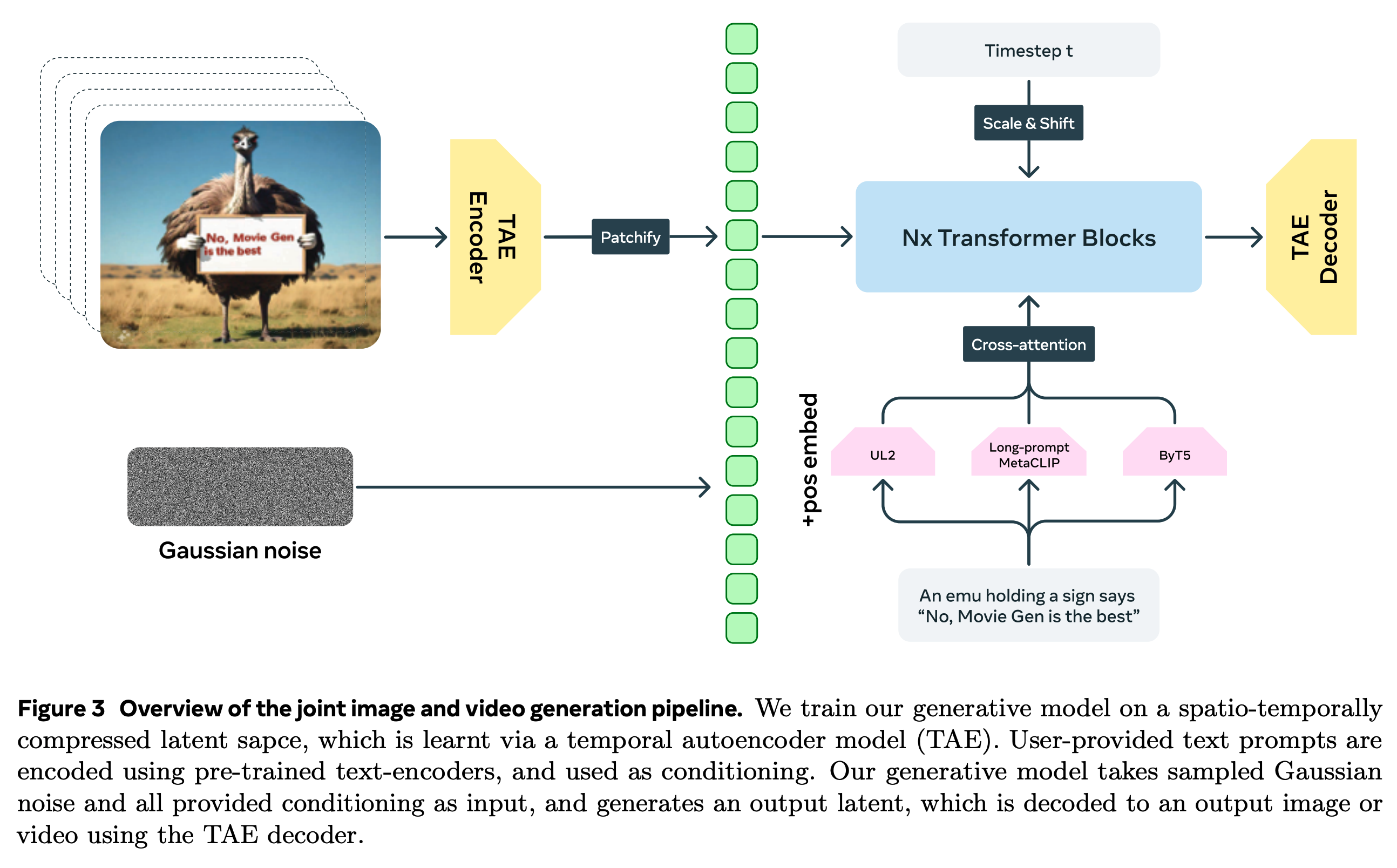
Meta 提出了 Movie Gen Video 这个统一的大模型来同时完成 T2I 以及 T2V 任务,模型将静态图像视为视频中的一帧,从而进行图像和视频生成的联合训练,即 Joint Image and Video Generation,使得模型可以同时生成图像和视频。
作者认为视频数据较为复杂,文本图像对的训练数据可以更好地帮助模型提高泛化性能。
下图展示了图像和视频联合生成的 pipeline。
多阶段训练策略
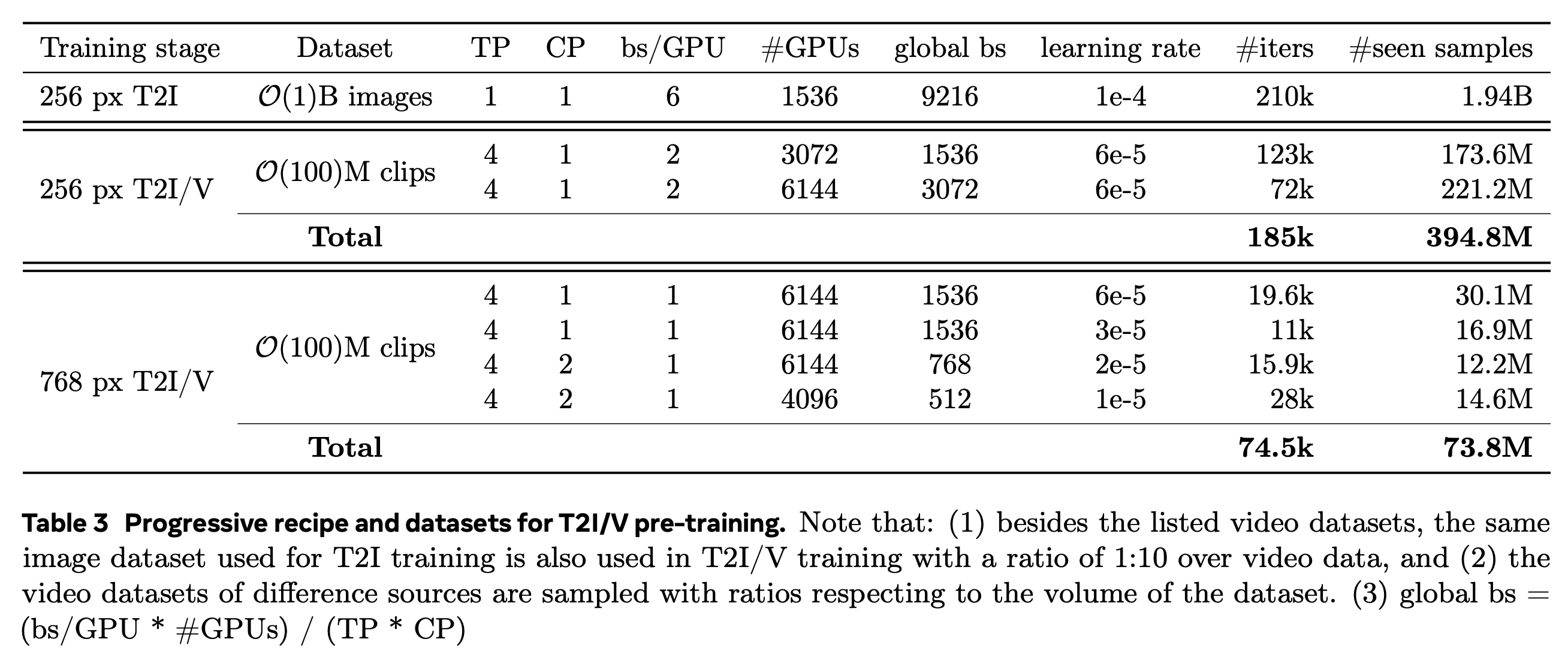
为了提高训练效率和模型的扩展能力,作者采用了多阶段的训练过程。
-
首先是 T2I 预热训练阶段。作者发现直接从头训练图像视频联合生成模型 T2I/V 会导致拟合缓慢,因此首先单独对 T2I 模型进行训练,作为预热阶段,并且在预热训练在较低分辨率(256 px)上进行,可以在相同��的计算开销上以更大的 batch size 训练更多的数据。
-
其次是图像视频联合生成模型 T2I/V 训练阶段。
为了可以成功实现联合训练,作者双倍增加了的空间位置编码层(spatial positional embedding layers)来适应更丰富的宽高比,同时增加了更多的时间位置编码层(temporal positional embedding layers)来支持多帧数图像(视频)的输入。
然后进行高分辨率的 T2I/V 联合训练。
-
在高质量的视频数据集上通过 Supervised Finetuing(监督微调,SFT)来优化生成质量。
-
最后可以后训练(Post Training)的方式来为 Movie Gen 增加个性化角色视频生成以及视频精确编辑等能力。
TAE(Temporal AutoEncoder)
为了提高效率,作者提出了 TAE 模型将像素空间的视频和图像压缩到经过学习的时空压缩隐式空间(learned spatial-temporally compreseed latent space),并且学习从隐空间中生成视频。

TAE Architecture(TAE 结构)
TAE 的设计采用了 LDM 使用的 Image Encoder 结构并且在时间维度进行扩展:
-
1D 时间卷积(Temporal Convolution):在每个二维空间卷积(2D spatial convolution)之后加入 1D 的时间卷积。
这使得模型能够捕捉数据的时间变化特征,从而适应视频的帧间动态变化。在视频生成中,帧之间存在时间上的连续性,时间卷积通过沿时间维度进行卷积操作,使得模型能够从连续帧中提取时间相关的信息。每一帧不仅通过空间卷积捕捉其内容,还通过时间卷积捕捉其与前后帧之间的动态关系。这种操作通过引入 1D 卷积来进行,保证了时间维度上的特征捕获。
-
1D 时间注意力机制(Temporal Attention):在每次空间注意力(spatial attention)之后加入 1D 的时间注意力机制。
帮助模型更好地关注视频序列中不同时间点的重要特征。通过在空间注意力之后加入 1D 的时间注意力,模型可以更好地理解视频序列中的时间依赖关系,即哪些时间点的特征对最终生成结果至关重要。这种注意力机制使模型能够在生成过程中关注到不同帧之间的关键时刻,提高视频的生成质量。
在将数据空间中的原始视频压缩到时空隐空间中的时间维度降采样过程中,模型采用步长为 2 的卷积操作对视频数据进行压缩,通过这种方式减少时间维度上的冗余信息。而在上采样过程中,模型使用最近邻插值法恢复时间维度的信息,再通过卷积来平滑和补充细节。这一过程保证了视频长度的灵活性,能够处理不同长度的视频序列�。
在下采样中采用在时间维度进行有步长的卷积方式来完成可以使模型能够处理任意帧长度的视频,包括图像(单帧视频),下图展示了时间维度卷积下采样的流程以及计算。
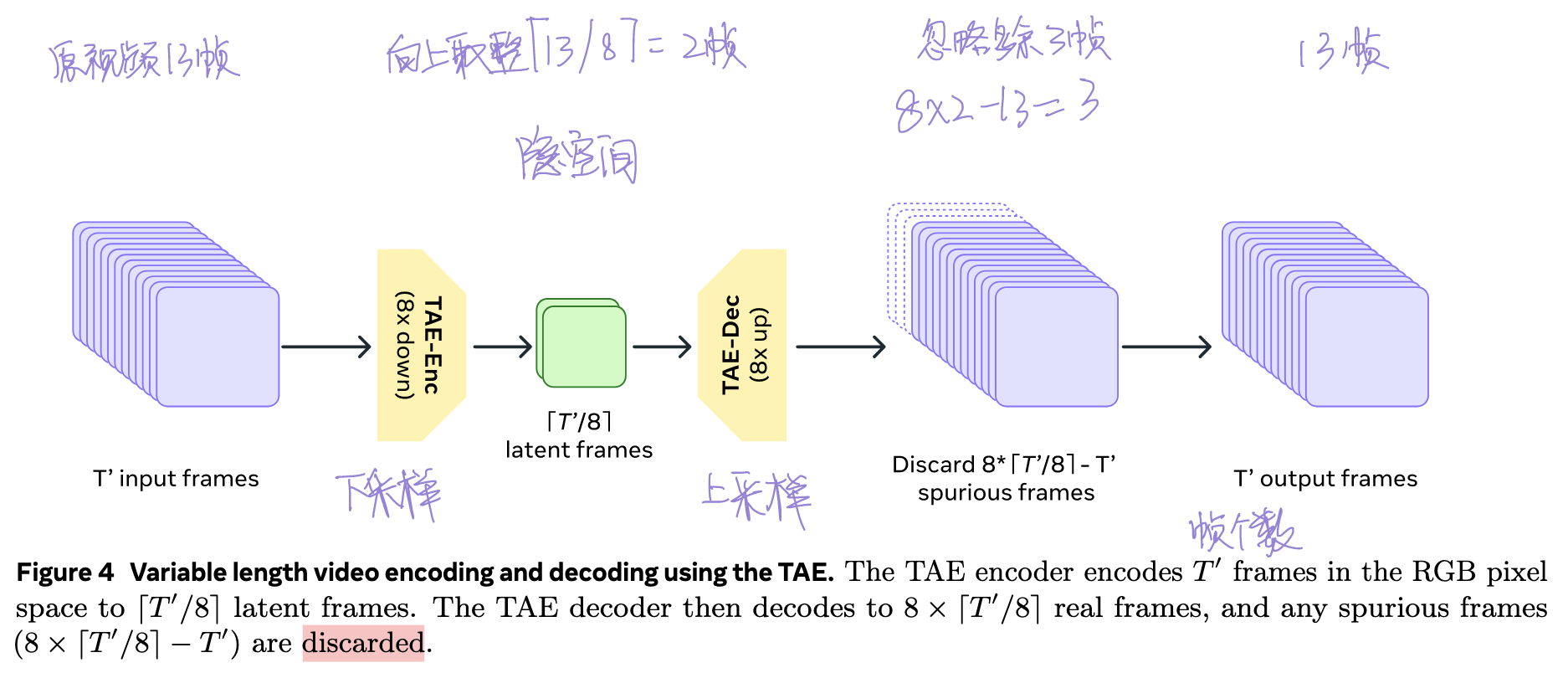
Improvements to the Training Objective(损失函数的优化)
作者发现如果 TAE 使用经典的 VAE 损失函数(Reconstruction Loss、Discriminator Loss、Perceptual Loss)进行训练会在数据空间解码出的视频中出现伪影点,如下图所示。
在 Latent Code 中伪影点位置出现了方差较大的取值,作者认为这是由于模型在伪影点学习存储了全局信息而导致的。

为了解决这一问题,作者在损失函数中加入了正则项来惩罚模型在 latent code 中生成偏离全局方差的值的行为,具体公式如下所示。

Efficient Inference using Temporal Tiling(使用时间分片来提高推理效率)
由于算力和存储的限制模型直接处理和生成分辨率较高的长视频(如 16 秒的 1080p HD 视频)具有很大的困难,因此作者采用了时间分片(Temporal Tiling)策略,将输入视频以及条件 latent code 沿时间维度进行 tiling,使用 tile 来代替 frame,每一个 tile 的大小统一。
在模型处理时,对每一个 tile 进行 encode 和 decode,在输出时将每个 tile 进行 stitch。
在 tiling 时,由于每个 tile 的帧数需要统一,很有可能会出现重叠(overlaps),因此在输出进行 stitch 时,需要进行额外的加权平均方式来对相邻的 tile 进行混合(blend),分片策略的推理 pipeline 如下图所示,使得输出视频的帧过渡更加平滑。
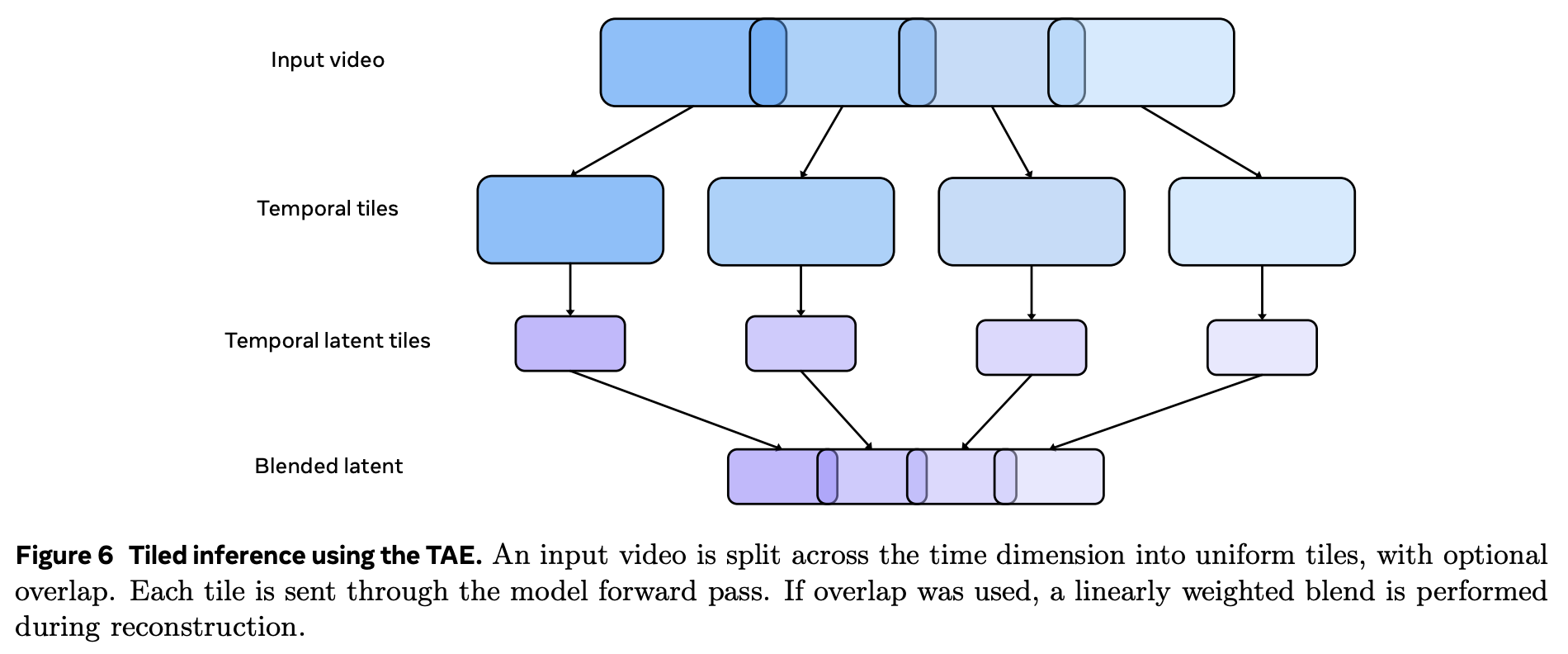
在 stitch 时具体的混合(blend)策略如下所示:
在 tile blending 时,对于相邻的帧 和 ,
其中 是 overlapping frames 帧数 的索引,。
Training Objective(训练目标与损失函数,引入 Flow Matching)

在 Movie Gen Video 模型中,引入了 Flow Matching 的生成框架。流匹配(Flow Matching)它在生成过程中引导模型从噪声逐步逼近真实数据分布。流匹配通过解决微分方程来控制从初始噪声到生成目标的过程。
流匹配的目标是通过微分方程(ODE)来定义生成路径,即让模型学习如何从一个随机初始化的噪声逐步转换为目标数据(如图像或视频)。
训练阶段的工作机制
-
从噪声开始训练:
- 训练的起点是从标准正态分布中采样出的噪声。模型的任务是学习如何将这个噪声转化为符合数据分布的图像或视频。
- 流匹配的关键在于对时间的处理。不同于分数模型的扩散过程,这里通过 ODE 定义了生成路径,并通过优化过程学习如何随着时间演化数据表示 。
-
时间维度控制与 TAE 的作用:
- Movie Gen 模型中的 **TAE(Temporal Autoencoder)**在编码图像和视频时,会引入时间相关参数(如 1D 时间卷积、时间注意力机制),这使得模型能够学习视频中的时间动态。这对于流匹配至关重要,因为时间卷积使得生成过程中每个时间步都能被显式建模。
- 流匹配的任务是学习从初始噪声到真实数据的平滑过渡,TAE 为这个过程提供了对时间维度的细粒度控制。因此,流匹配不仅在生成过程中影响时间演化,还通过 TAE 的时间建模来确保生成的视频帧之间的连贯性。
-
空间与时间建模的结合与 Transformer 的作用:
- Movie Gen 模型中的 Transformer 通过自注意力机制,负责捕捉图像和视频中空间和时间的长程依赖关系。在视频生成过程中,Transformer 的作用是确保生成的视频帧在空间结构上是一致的,并在时间维度上保持逻辑连贯性。
- 流匹配与 Transformer 结合后,生成过程中的每一个时间步不仅会考虑时间维度的动态变化(由流匹配控制),还会通过 Transformer 捕捉到空间和时间上的依赖关系。这使得每一个生成的视频帧既能够遵循流匹配的演化轨迹,又能够在空间和时间上保持一致性。
-
训练中的优化目标:
- 在训练过程中,流匹配的目标是通过最小化生成路径与真实数据分布的差异来优化模型。这个过程类似于分数模型中通过分数函数指导优化,只不过这里的优化是通过 ODE 求解每个时间步的变化率 来进行。
- 模型通过计算从噪声到数据分布的路径,学习如何将采样的噪声逐步演化成目标图像或视频。这种逐步演化过程在每个时间步都被 ODE 求解器所控制,优化的目标是让模型生成的路径尽可能逼近真实数据的路径。
推理阶段的工作机制
-
初始采样: 首先, 从一个标准正态分布中采样一个初始的噪声向量 。这个噪声向量作为推理的起点, 代表了模型生成过程的初始状态。
-
ODE 求解: 通过模型估计出的 (即噪声随时间的变化率), 使用常微分方程(ODE)求解器来计算下一个状态 。ODE 求解器的任务是在给定初始状态 和模型估计的导数信息的基础上,逐步逼近生成的图像或视频帧的最终状态。
-
求解器配置的设计选择:
在具体的 ODE 求解器配置中, 有多种设计选择, 如:
- 求解器阶数:可以选择一阶或更高阶的求解器, 阶数越高, 求解精度越高, 但计算复杂度也相应增加。
- 步长大小:求解器在每次迭代中前进的步长会影响生成过程的速度和精度, 步长越小, 生成的图像或视频细节越多, 但计算时间也会增加。
- 容差(Tolerance):设置 ODE 求解的容差可以控制解的精度与计算成本之间的平衡。
-
简单一阶欧拉求解器:论文中提到, 实际应用时, Movie Gen 模型使用了一个简单的一阶欧拉求解器(Euler ODE solver),这个求解器通过逐步估算下一时间步的状态, 适合高效地处理推理阶段的计算。
离散时间步长:模型根据特定的 个离散时间步长进行推理, 这些时间步长是为模型量身定制的, 用以优化生成效果。
Joint Image and Video Generation Backbone Architecture(骨干网络)
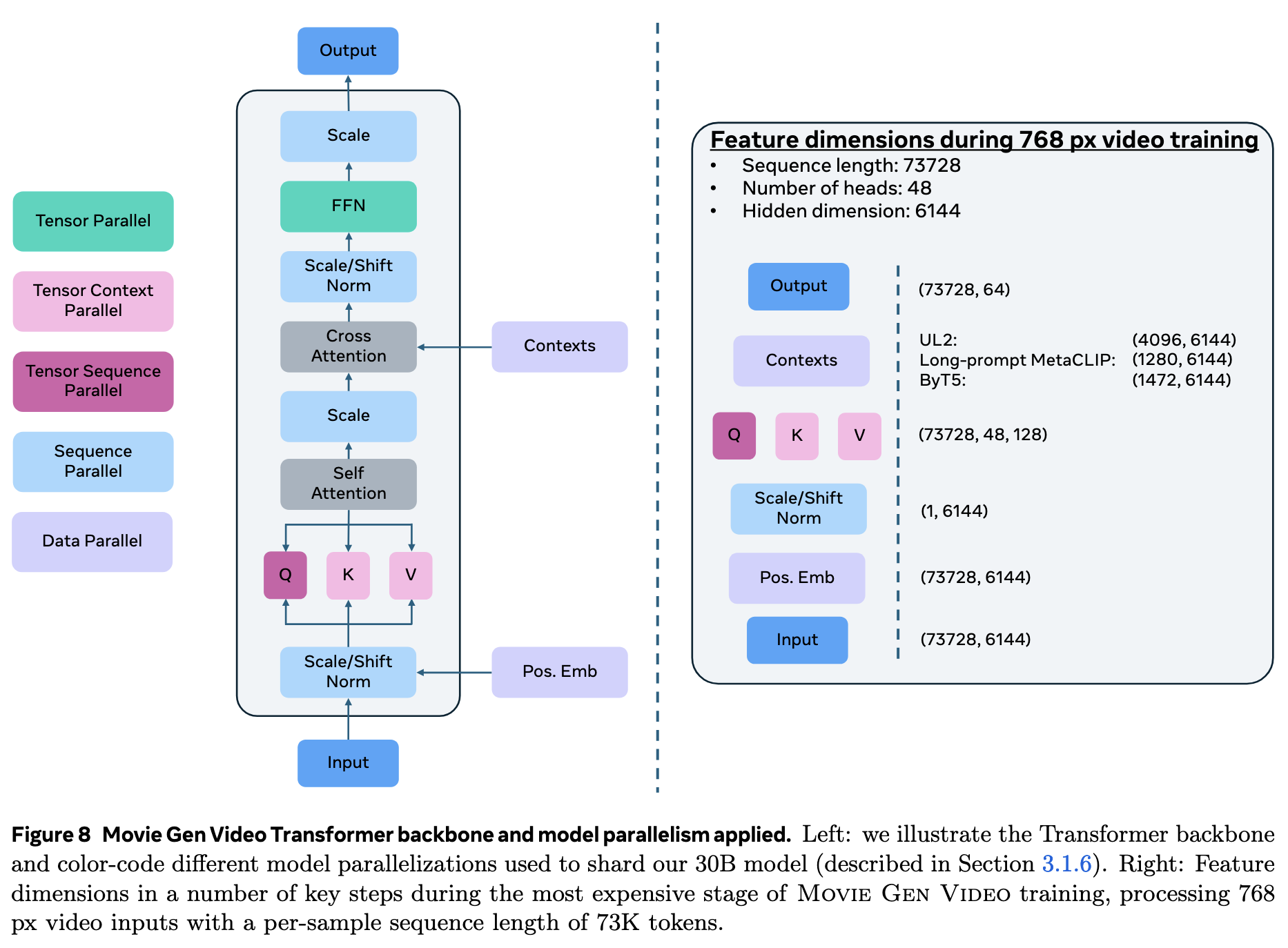
如下图所示,Transformer Backbone 在时空压缩的隐空间中学习如何生成视频的隐式代码(latent code),对于像素空间的视频 经过时空压缩后得到 的 latent code,latent code 在送入 Transformer Backbone 之前还需要经过以 3D 卷积为方式实现的 patchify 并最终展平。
作者使用了与 LLaMa3 相似的 Transformer Backbone(即使用了 RMSNorm、SwiGLU 的版本),并且主要做了以下三个改变来适应 Flow Matching 的视频生成:
- 为了使输入的文本条件产生引导作用,在前馈网络 FFN 与自注意力机制之间加入了交叉注意力,同时使用了多个 Text Encoder 来更好地提升条件引导表现。
- 加入了 Adaptive Layer Normalization Block(adaLN)来适配 Transformer 中的时间步。
- 使用双向注意力(bi-directional attention)代替单向注意力(casual attention)。
Rich Text Embedding and Visual-text Generation(丰富的文本嵌入以及视觉文本生成)
Movie Gen Video 中使用了两类共三种不同的预训练 Text Encoder 来完成文本嵌入和理解。分别为语义级别的 UL2、Long-prompt MetaCLIP 以及字符级��别的 ByT5。
- UL2(语义级别):在大量纯文本数据集上训练,可以提供丰富的文本推理能力。
- Long-prompt MetaCLIP(语义级别):通过在更长的输入文本数据上微调 MetaCLIP 得到的,输入 token 数从 77 增加到了 256。具备多模态的文本-视觉对齐能力。
- ByT5(字符级别):ByT5 主要对输入文本中有关要求在输出的视觉图像中生成文字相关图形的 token 进行编码。
三个 Text Encoder 的输出 Text Embedding 在分别经过线性投影以及层归一化后得到 6144 维的向量,并通过 concat 连接起来。
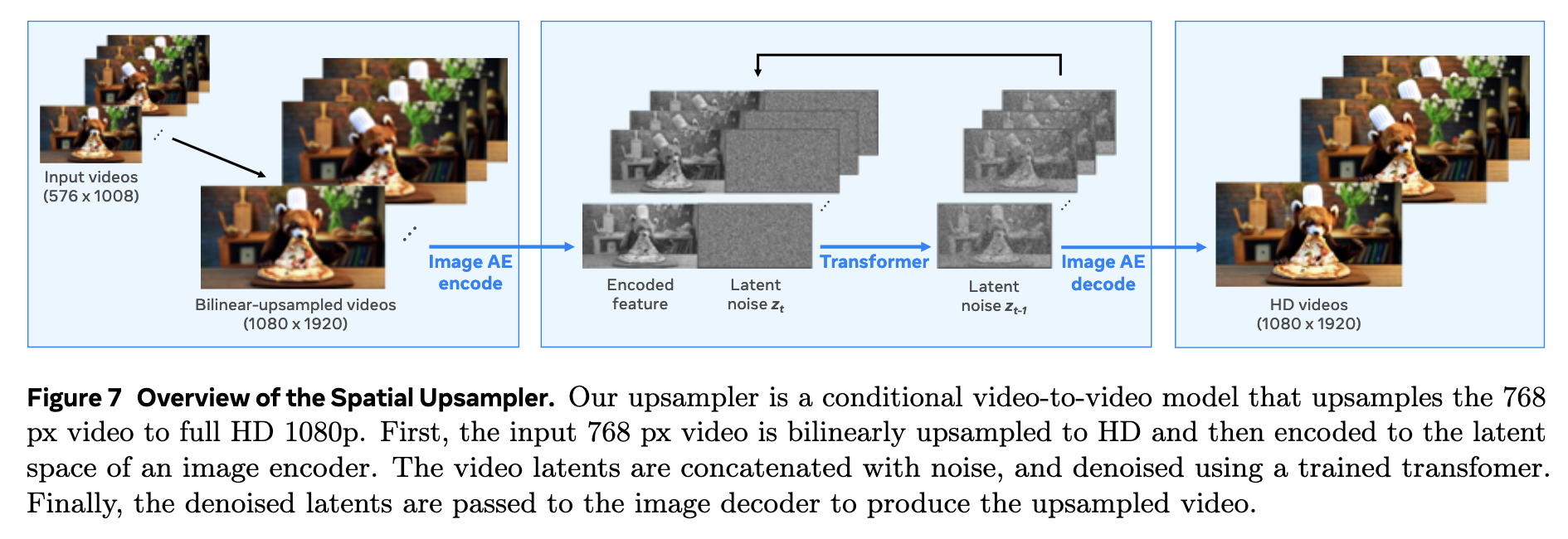
Spatial Upsampling(空间上采样)
Movie Gen Video 单独设计了一个 Spatial Upsampler Transformer 来进行超分辨率扩展,将从 TAE Decoder 中输出的 768 px 视频上采样为 1080p 的高清 HD 视频。分开的设计使得 T2V 模型可以处理更少的 token,因此减少了直接生成高分辨率视频的计算开销。
如下图所示,空间上采样模型的任务可以认为是一个 Video-to-Video 的生成任务。
-
低分辨率的视频首先在像素空间通过双线性插值(bilinear interploation)扩展到期望的高分辨率。
-
扩展后的高分辨率像素空间视频通过一个 VAE 的 Encoder 编码到 Latent Space 中。
-
隐空间中的视频生成模型(Spatial Upsampler Transformer)生成重建后高分辨率视频的 latent code。
该 Transformer 模型是 T2V Transformer 的小型变种,拥有 7B 的参数量,并由一个在 1024 px 分辨率图像数据集上预训练的 T2I Transformer 来初始化参数。
编码后的原始视频与��生成的输入在通道维度进行 concatnation 后被送入 Spatial Upsampler Transformer 中。
Implementation details. Our Spatial Upsampler model architecture is a smaller variant (7B parameters) of the text-to-video Transformer initialized from a text-to-image model trained at 1024 px resolution, allowing for better utilization of high-resolution image data. The Spatial Upsampler is trained to predict the latents of a video which are then decoded frame-wise using the VAE’s decoder. Similar to (Girdhar et al., 2024), the encoded video is concatenated channel-wise with the generation input and is fed to the Spatial Upsampler Transformer. The additional parameters at the input, due to concatenation, are zero initialized (Singer et al., 2023; Girdhar et al., 2024). We train our Spatial Upsampler on clips of 14 frames at 24 FPS on ~400K HD videos.
-
最后通过 VAE 的 Decoder 映射到像素空间得到超分辨率重建的结果。