生成式对抗网络(GAN)
How to pronounce Adversarial?
/ˌædvərˈseriəl/
引言
将随机分布作为输入
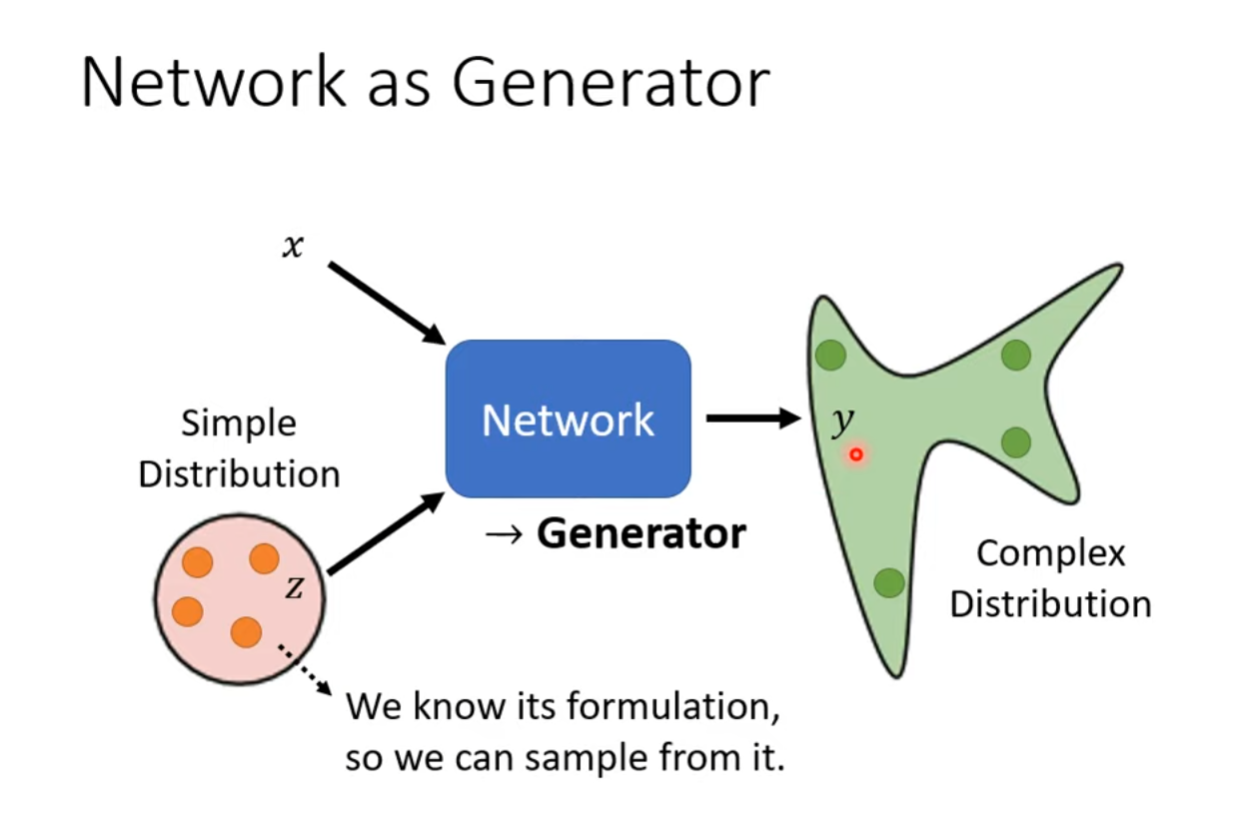
生成器(Generator)通常接收一个来自潜在空间(latent space)的随机向量作为输入。这个潜在空间通常是一个随机分布,比如均匀分布或正态分布。生成器的任务是将这个随机向量映射成与训练数据相似的样本。
为什么要添加分布
当需要解决的任务需要富有“创造力”时,即根据不同的输入,可以产生多个不一样且正确的输出时。这样的设计使得生成器能够生成多样性的样本,因为每个不同的随机向量都可能导致生成器输出不同的样本。在训练过程中,通过不断调整生成器的参数,使得生成器的输出在数据分布中更难以被判别器区分。
核心思想
GAN的工作原理:
- 生成器生成数据: 生成器从潜在空间中采样并生成一些数据。
- 真实数据与生成数据进入判别器: 真实数据和生成器生成的数据一起输入判别器。
- 判别器训练: 判别器被训练来正确分类真实数据和生成数据。
- 生成器训练: 生成器被训练来生成能够欺骗判别器的数据。生成器的目标是生成足够逼真的数据,以至于判别器无法准确区分真假。
- 迭代: 生成器和判别器交替训练,迭代进行,直到生成器生成的数据足够逼真。
训练的目标:
- 生成器目标: 生成更逼真的数据,以欺骗判别器。
- 判别器目标: 区分真实数据和生成数据,提高对真实数据的分类准确性。
GAN的训练是一个博弈过程,生成器和判别器相互竞争,最终达到平衡,生成器生成的数据足够逼真,判别器也无法准确判别真伪。这种模型在图像生成、风格转换等任务中取得了显著的成功。
具体结构与作用
GAN(Generative Adversarial Network,生成对抗网络)包括两个主要的组件:生成器(Generator)和判别器(Discriminator)。这两个组件通过对抗训练的方式一起学习。
- 生成器(Generator): 它负责生成与训练数据相似的新样本。生成器接收来自潜在空间(latent space)的随机向量作为输入,并输出一个与训练数据类似的样本。生成器的目标是欺骗判别器,使其无法区分生��成的样本和真实的训练数据。
- 判别器(Discriminator): 它负责判别输入的样本是真实的训练数据还是生成器生成的假样本。判别器的目标是尽可能准确地分类输入的样本。
GAN的核心思想是通过对抗过程训练生成器和判别器,不断提高它们的性能。生成器试图生成逼真的样本,而判别器试图正确地区分真实样本和生成样本。这个对抗的训练过程可以被视为在两个分布之间进行的最优控制。
生成器(Generator)
- 结构: 生成器是一个神经网络,通常是一个反卷积神经网络(Generator Network),其输入通常是一个随机噪声(潜在空间中的点),输出是与训练数据相似的图像或数据。
- 作用: 生成器的目标是学习生成与真实数据相似的数据。通过迭代训练,生成器的参数被调整,使其生成的数据能够愈发逼真。
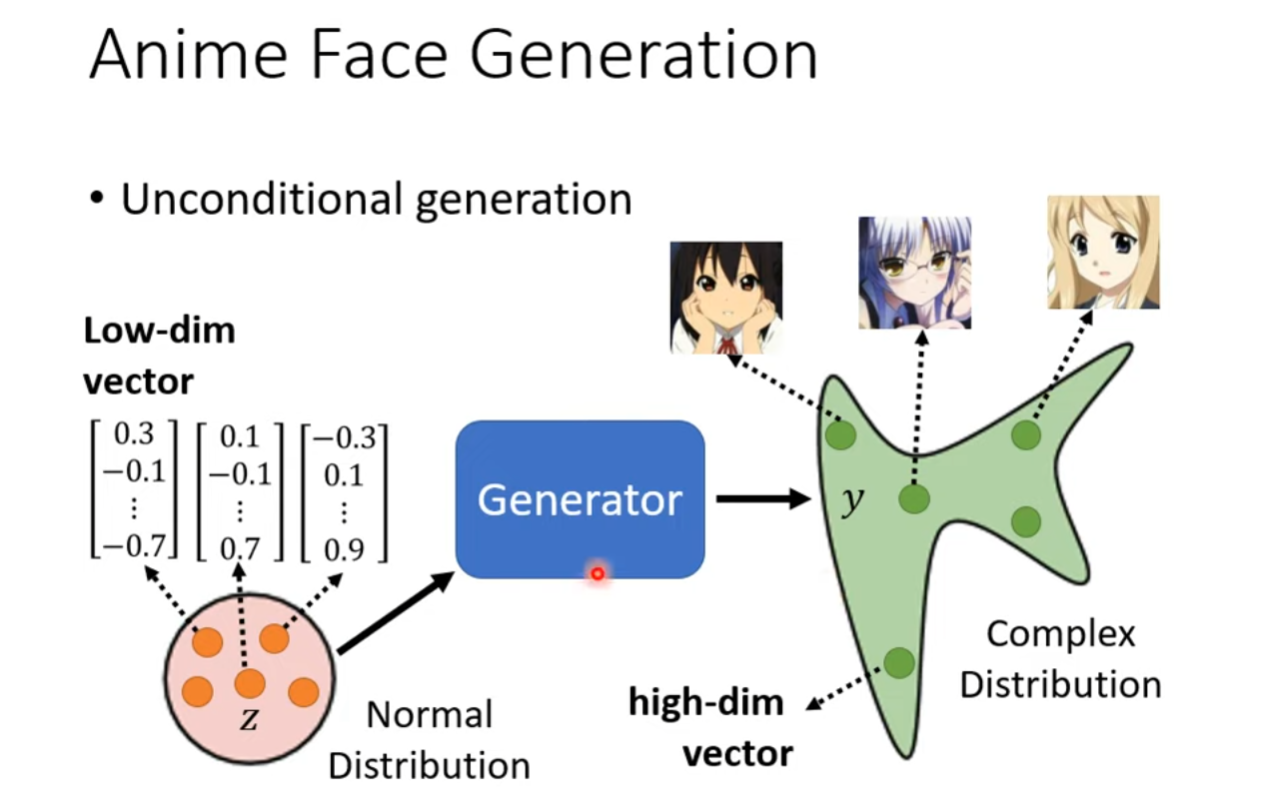
Unconditional Generation
Unconditional generation(无条件生成)指的是在生成模型中生成样本时,不受任何条件的约束。在这种情况下,生成器仅根据其学到的分布生成数据,而无需关注特定的输入条件或上下文。
对于生成对抗网络(GAN)或变分自动编码器(VAE)等生成模型,unconditional generation通常表现为从潜在空间中采样,然后将这些样本输入生成器,以生成新的、与训练数据相似的样本。这种生成�方式是随机的,因为每次从潜在空间中采样都会导致生成不同的样本。
Conditional Generation
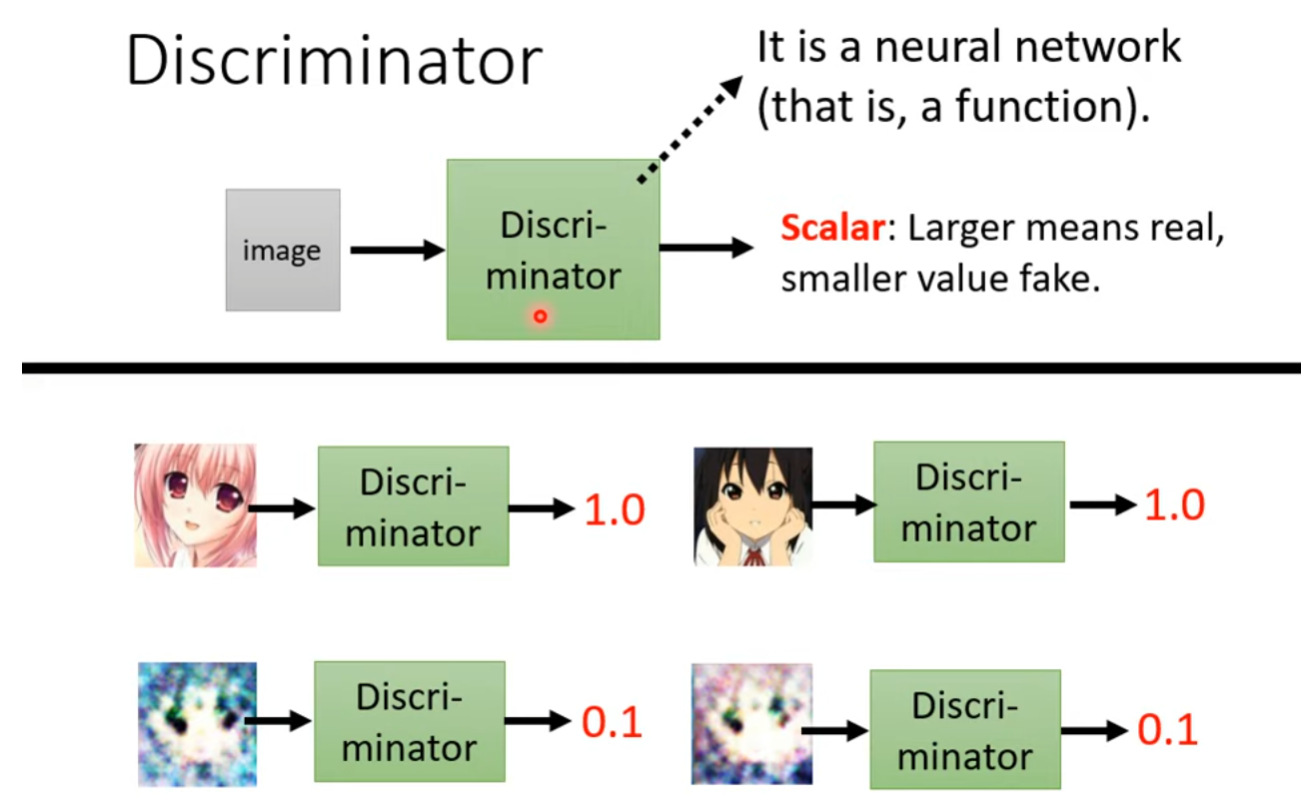
判别器(Discriminator)
- 结构: 判别器是一个二元分类器,通常是一个卷积神经网络(Discriminator Network)。它的输入可以是真实数据或生成器生成的数据,输出是一个概率,表示输入数据是真实数据的概率。
- 作用: 判别器的目标是学习区分真实数据和生成器生成的数据。它被训练成对真实数据给出高概率,对生成的数据给出低概率。
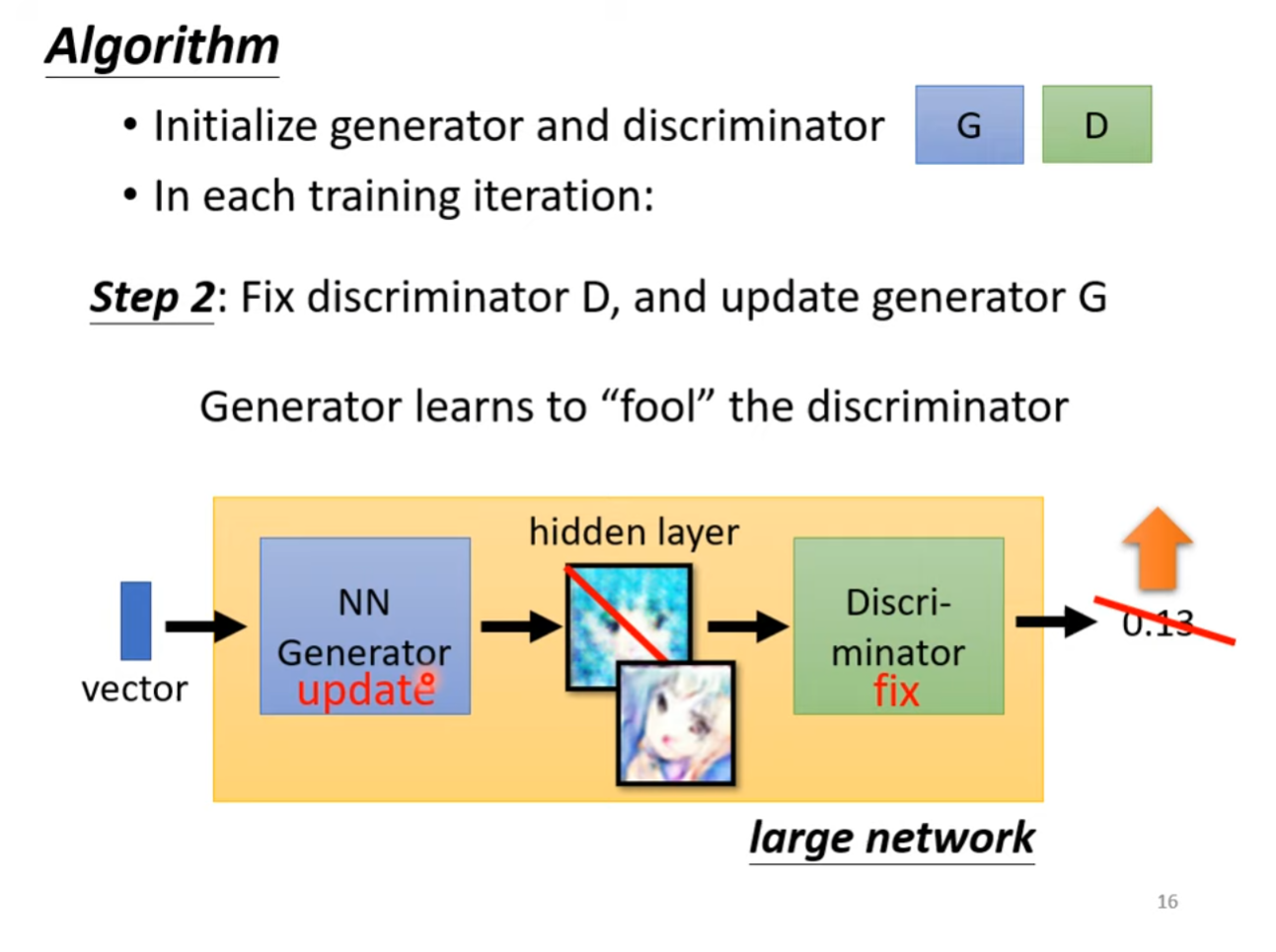
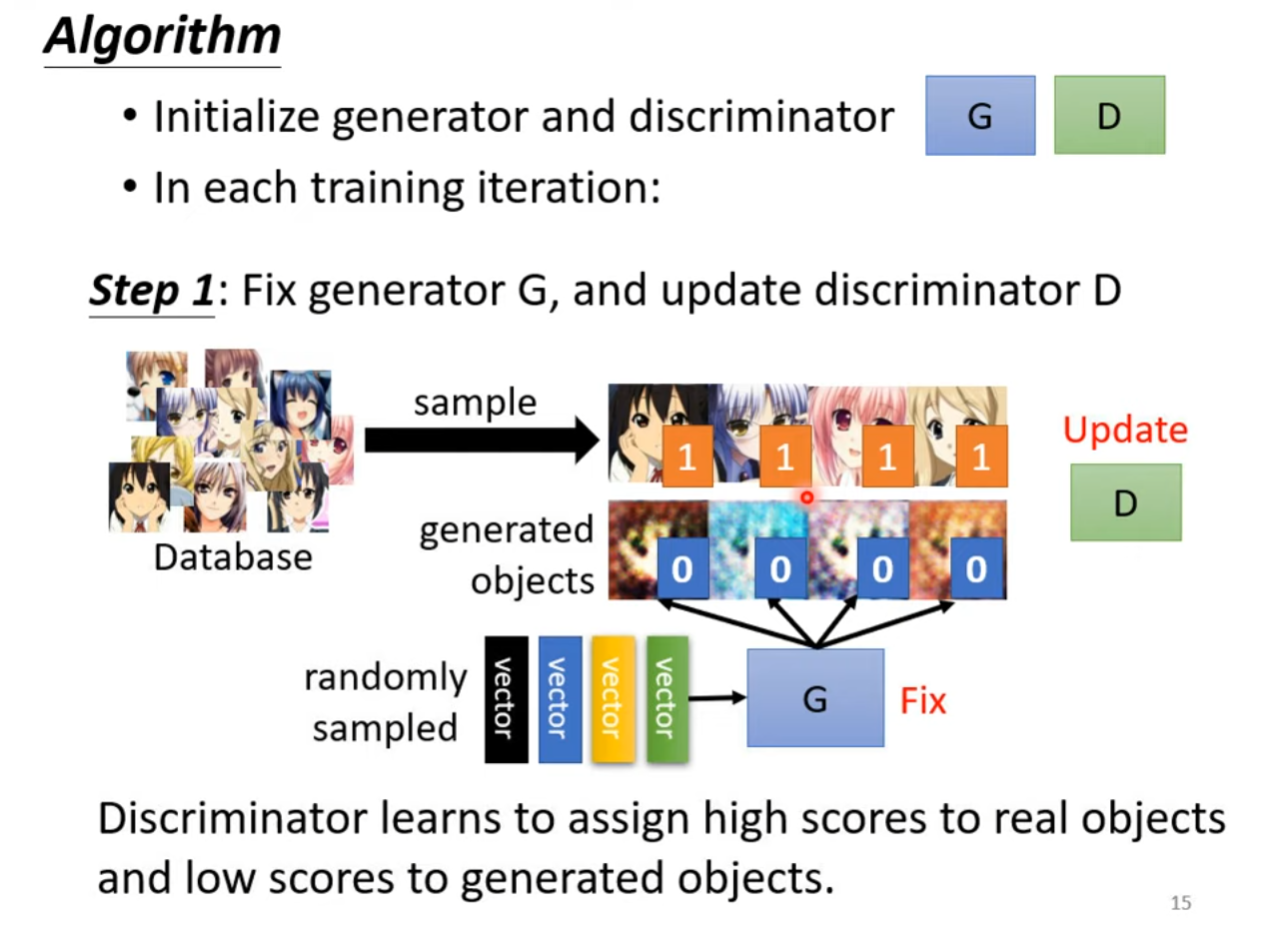
训练算法
首先随机初始化生成器和判别器,接下来在每一轮训练中重复以下策略。
第一步,在生成器通过随机噪声神生成样本后,固定生成器的参数,将生成器产生的输出与训练资料中的标签作为判别器的输入,判别器为每个输入��样本打分,代表其为真实样本的概率。
为了最小化损失函数使得判别器为真实样本赋分更高,为生成样本赋分更低,设计以下损失函数:
其中,是判别器的输出,是真实样本,是数学期望。
其中,是生成器的输出,是随机噪声,是数学期望。
将真实样本和生成样本的损失相加,形成判别器的总体损失。
最小化损失函数,更新判别器的参数。
第二步,在判别器参数更新后,固定判别器的参数,随机分布的向量再次输入至生成器中,得到生成样本,此时生成样本被送入参数固定的判别器中得到生成样本属于真实样本的概率。在生成器的训练过程中,我们的目的是让生成器生成的样本尽可能的接近真实样本。
其中,是生成器的输出,是生成样本输入到判别器后的输出,是随机噪声,是数学期望。