图像生成和视频生成基座模型
图像生成基座模型
四种生成范式
GAN
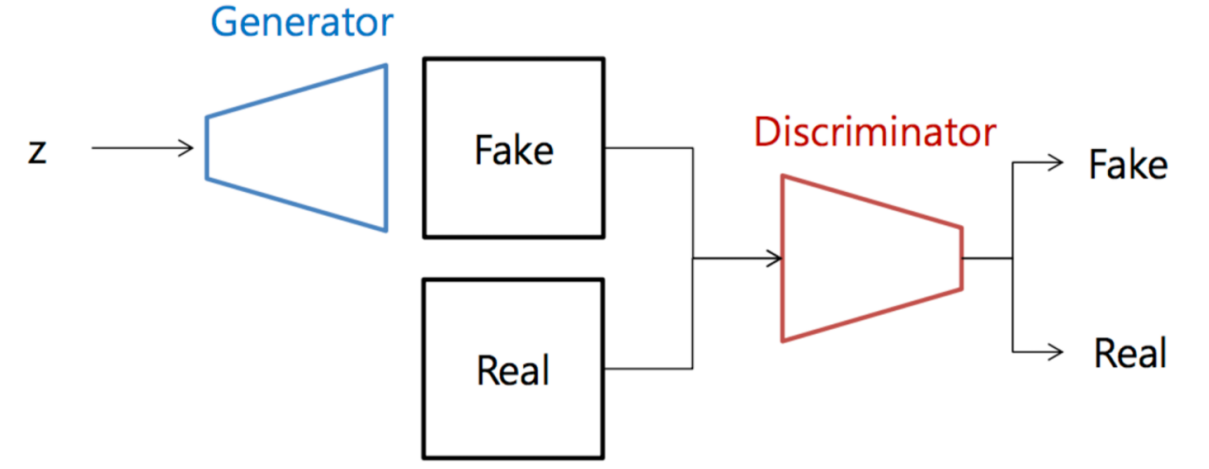
使用对抗生成策略,判别器根据真实图像判断生成器生成的图像是否逼真,二者交替训练。
Autoregressive(AR)
自回归生成范式,利用输入自身之前各期 来预测本期 的表现。在图像生成中,自回归模型可以逐像素或逐块生成图像,每一步的生成基于之前已经生成的部分。自回归模型的优点在于能够捕捉图像中的复杂依赖关系,从而生成更加逼真的图像。
代表模型:VAE、VQVAE(2017)
VAE 和 VQ-VAE 都通过学习数据分布的潜在表示来生成新的样本。VAE 使用高斯分布来表示潜在空间,而 VQ-VAE 使用离散的代码簿来表示潜在��空间。
具体来说,VAE 的工作原理是通过一个编码器将输入数据映射到一个潜在空间,然后通过一个解码器将潜在空间中的向量重构为原始数据。在训练过程中,VAE 会学习到数据分布的潜在表示,并能够生成与训练数据类似的新样本。
VQ-VAE 的工作原理与 VAE 类似,但它使用离散的代码簿来表示潜在空间。VQ-VAE 首先将编码器输出的向量进行量化,将其映射到代码簿中的最近向量。然后,解码器使用代码簿中的向量来重构原始数据。VQ-VAE 的优势在于,它可以学习到数据中的离散结构和语义信息,并可以避免过拟合。
代表模型:VQGAN(2021)
代表模型:ViT-VQGAN(2022)
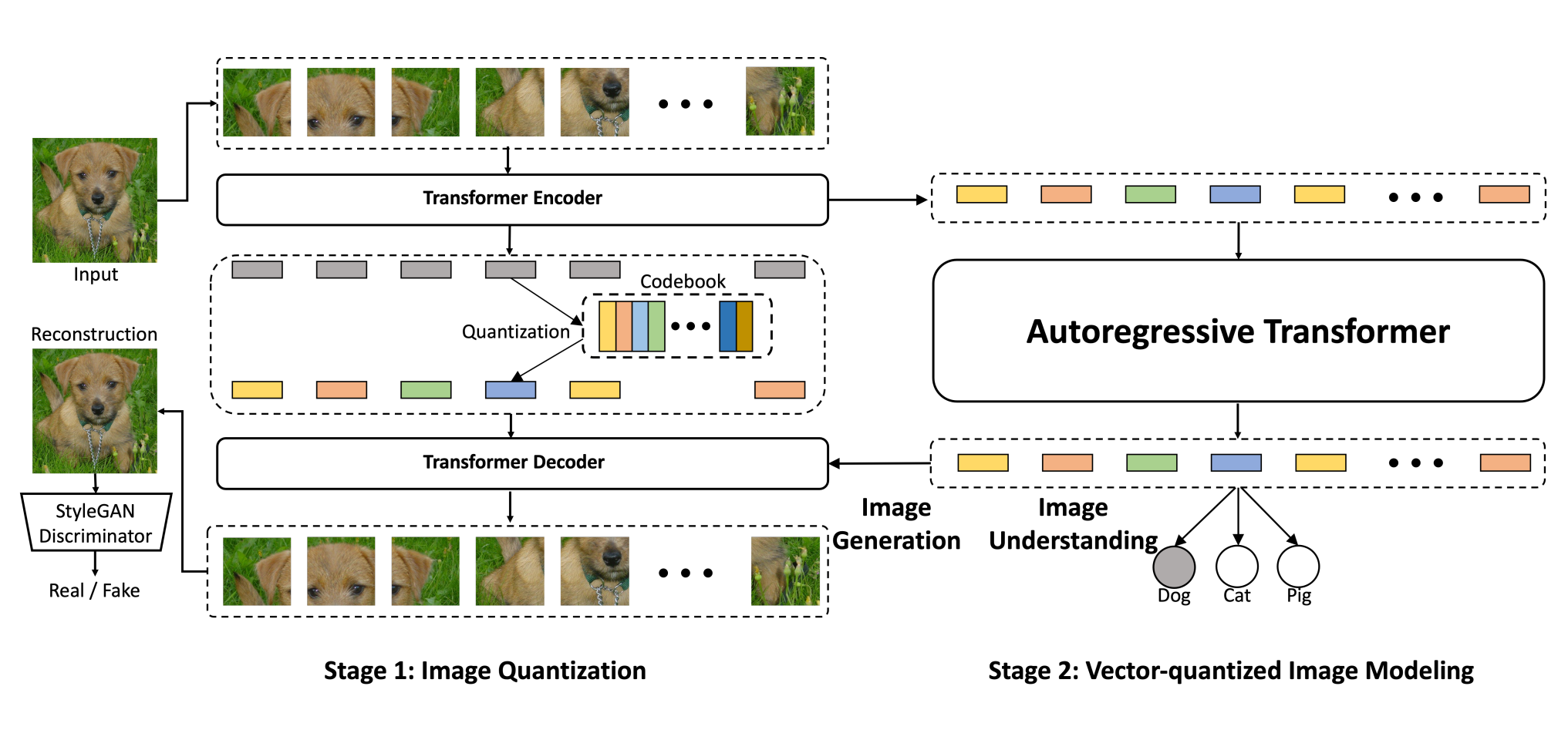
VQ (Vector Quantization) 的改进:在原有的 VQ-VAE 基础上进行了改进,通过引入更复杂的量化器和更强大的解码器,使得生成的图像质量得到了显著提升。
GAN (Generative Adversarial Network) 的结合:将 VQ 和 GAN 结合,利用 Style-GAN 的判别器来提升生成图像的细节和逼真度。
Transformer 的使用:将 VQ-VAE 和 VQGAN 的 Encoder、Decoder 中原来使用的 CNN 结构替换为 ViT。一是因为数据量丰富,二是 CNN 的归纳偏置对模型的约束是有限的,三是计算效率和重建质量更显著。
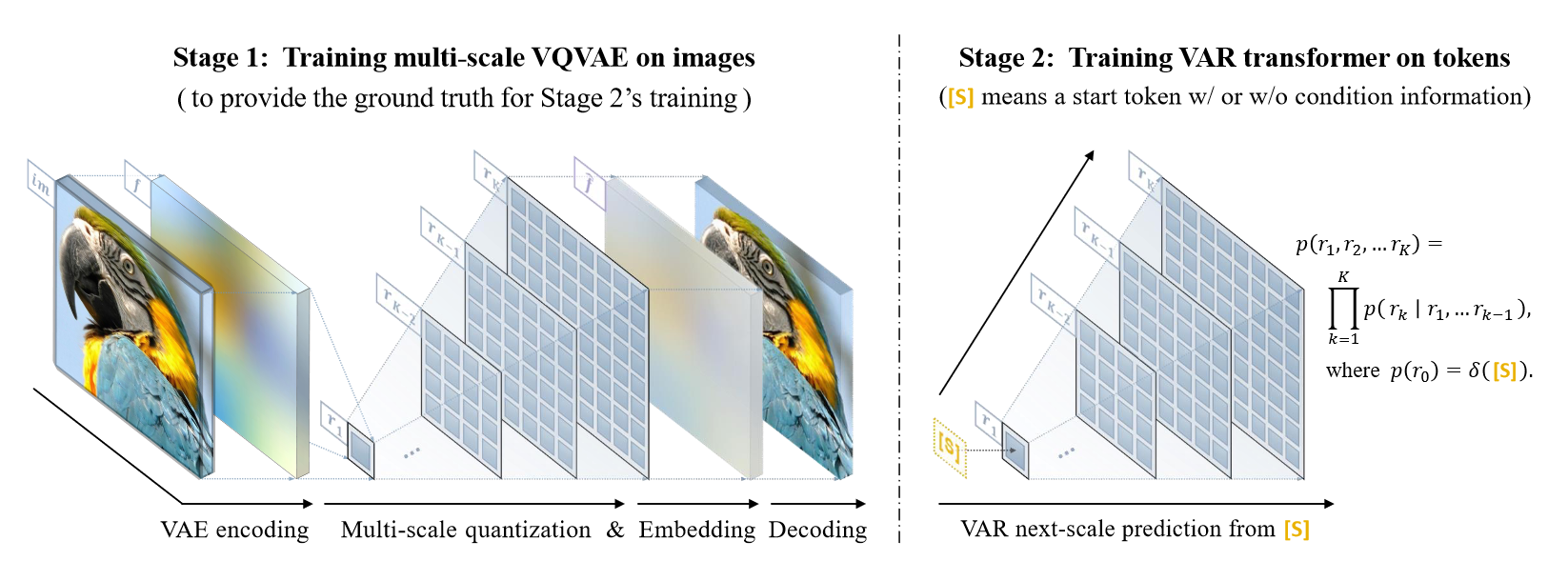
代表模型:VAR
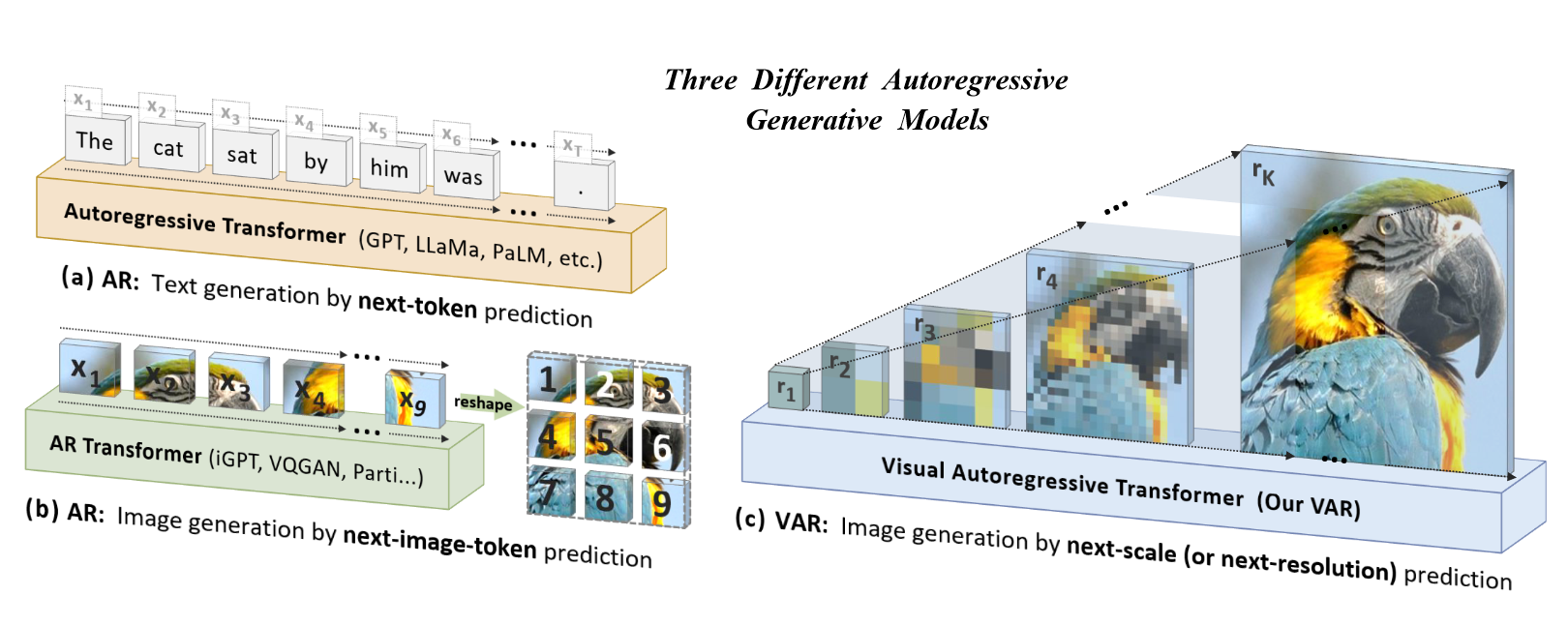
上图展示了不同方式的自回归生成模型,VAR 方法在每个时间序列节点上都根据之前各时间步的输出预测出当前时间步的,且每个时间步均预测出完整的目标图像,且分辨率随时间推移逐步提升至高清图像,即 next-resolution prediction。
Masked-prediction model(Non-AR)
代表模型:MaskGIT: Masked Generative Image Transformer
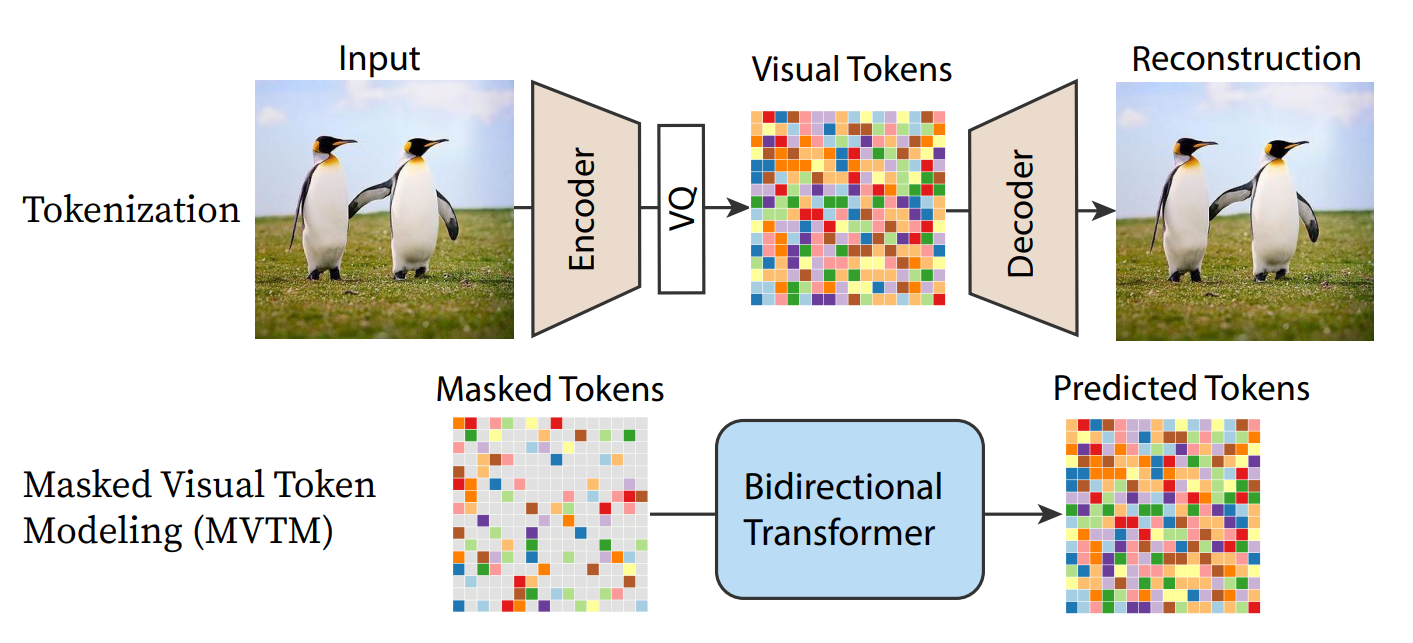
这种生成模型依赖一个预训练好的 VQGAN,能将图片 tokenize 成一组量化后的 visual tokens。VQGAN 编码图片得到的 tokens 是离散的,所有可能的 tokens 构成一个 codebook,假设其中包含 个 token 选项。MVTM 训练就是指给定 masked tokens,让网络预测这些被 masked 掉的 tokens。对于每个被 masked 掉的 token,网络给出一个 维向量预测当前 token 属于 codebook 中每个 token 的可能性,类似于完成一个 分类任务。
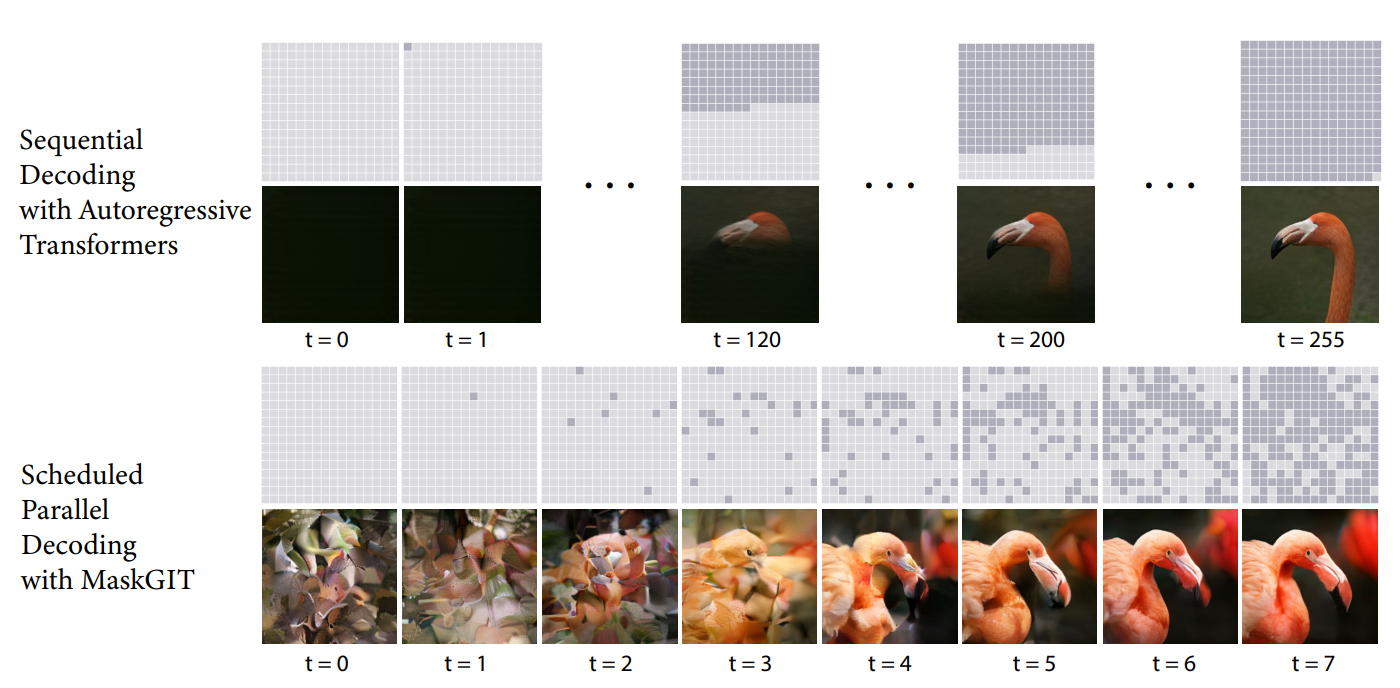
上图展示了传统 AR 模型和 MaskGIT 在推理过程中的区别。与之前 SOTA 使用的 Autoregressive 方法——逐行再逐列依次生成 image token 不同,MaskGIT 在推理时的每次迭代从一组 masked tokens 中预测出每个位置出现 visual token 的可能性,然后仅保留那些置信度足够高的位置的 visual token,然后继续将当前预测结果再送入网络进行下一轮预测,直到所有位置的 visual token 都被预测出来。与之前常用的自回归方法不同,每轮预测都是基于对图片的全局感知,可以并行预测。这样网络仅需 8 次前向传播就能生成高质量的图片。
顺序解码与 MaskGIT 计划并行解码的比较。第 1 行和第 3 行是每次迭代时的输入潜在掩码,第 2 行和第 4 行是每次迭代时每个模型生成的样本。MaskGIT 的解码从所有未知代码(浅灰色标记)开始,逐渐用更多更分散的预测并行填充潜表征(深灰色标记),预测标记的数量随着迭代急剧增加。MaskGIT 只用了 8 次迭代就完成了解码,而顺序法需要 256 轮。
代表模型:MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
Diffusion Model
如何训练优秀的生成基座模型?
- 数据:Re-caption 与 text encoder(T5)
- 结构:从 U-Net 到纯 Transformer,代表论文 Scalable Diffusion Models with Transformers
- 训练范式:使用 Rectified Flow 加速生成过程,参考链接 Diffusion学习笔记(十二)——Rectified Flow
视频生成基座模型
原文 URL:Video and 3D Generation