[CVPR 2023] Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
摘要
本文提出了Image-specific Prompt Learning(IPL)方法来解决风格迁移任务中生成模型从源域到目标域的适应问题。一个Latent Mapper来从源域图像中学习出包含图像特征且适应目标域的prompt,从而指导目标域生成器的训练。
This produces a more precise adaptation direction for every cross-domain image pair, endowing the target-domain generator with greatly enhanced flexibility.
训练资料是源域和目标域的文字标签以及源域的图像,并不需要目标域的图像。此外,IPL独立于生成模型,可以自由选择Diffusion Model或GAN等。
相关工作
Generative Model Adaption
Generative Model Adaption的任务是使在大规模源域图片上训练的生成模型适应到数据有限的目标域中,根据目标域训练资料的大小可以分为few-shot和zero-shot。
few-shot
对于few-shot任务,一般是通过有限的目标域训练集资料fine-tune预训练模型。
然而,fine-tune通常会导致过拟合。为了解决过拟合问题,通常使用的方法是施加强正则化、使用扰动法、跨域对齐或数据增强。
- 强正则化:Han Zhang, Zizhao Zhang, Augustus Odena, and Honglak Lee. Consistency regularization for generative adversarial networks. In ICLR, 2019.
- 扰动法:Sangwoo Mo, Minsu Cho, and Jinwoo Shin. Freeze the discriminator: a simple baseline for fine-tuning GANs. In CVPR Workshops, 2020.
- 跨域对齐:Utkarsh Ojha, Yijun Li, Jingwan Lu, Alexei A Efros, Yong Jae Lee, Eli Shechtman, and Richard Zhang. Fewshot image generation via cross-domain correspondence. In CVPR, 2021.
- 数据增强:Ngoc-Trung Tran, Viet-Hung Tran, Ngoc-Bao Nguyen, Trung-Kien Nguyen, and Ngai-Man Cheung. On data augmentation for GAN training. TIP, 2021.
zero-shot
对于零样本的图像生成模型的适应任务,NADA率先引入了CLIP模型来获取必须的先验知识,通过预训练大模型的语言理解能力实现在目标域只需要文字标签而不需要图片,将源域和目标域之间的差距编码为在CLIP空间上文字引导的适应方向。
此后,CVPR 2022发表的DiffusionCLIP使用了Diffusion模型代替NADA中的StyleGANs,获得了更好的特征保存能力。
然而这些方法都是采用了固定的适应方向,只包含基础的域知识,而不是图片特定的特征。在本文中,作者发现这种共享的、固定的适应方向会导致Mode Collapse(模式坍塌),因此提出了从每个源域图像中学习出多样且准确的prompt,为生成模型向目标域的适应提供更精确的方向。

Prompt Learning
Prompt工程最初是一种Knowledge Probing(知识探测)方法,给定完形填空(cloze-style)类的prompt,引导模型产生相对应的答案。
然而人工设计的prompt通常不是最优的,可能提供不准确的适应方向。为了解决这个问题,在NLP领域的Prompt Learning发展迅速,并随着视觉-语言大模型的发展,应用在了视觉任务中。
Kaiyang Zhou等人首先在图像分类任务中采用上下文优化,在词嵌入空间中对具有连续向量的上下文词进行建模。随后Prompt Learning在计算机视觉中的许多下游任务都得到了探索,例如目标检测、视频理解和迁移学习等。
主要方法
概述
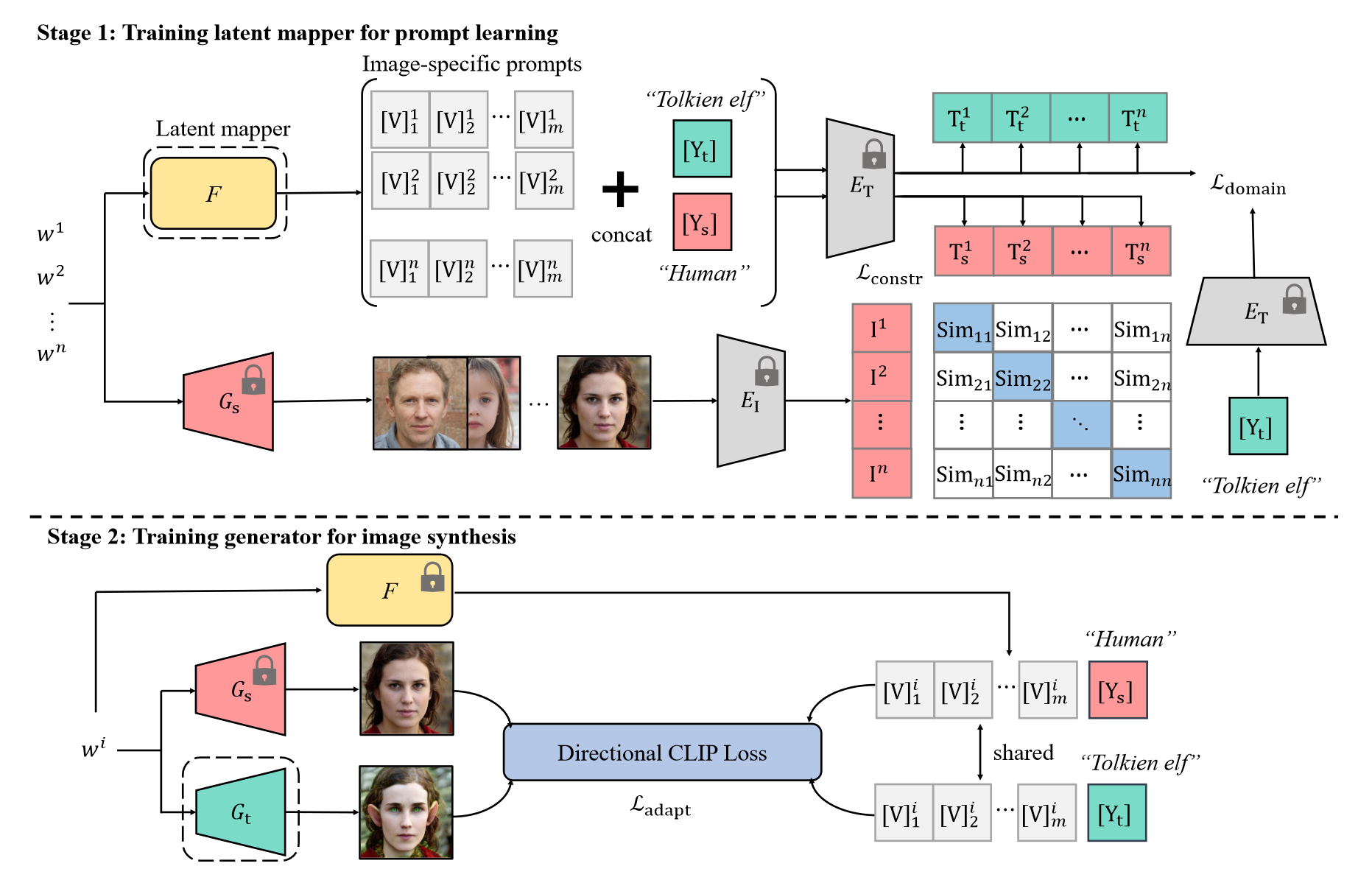
IPL方法分两个阶段。
第一阶段:训练Latent Mapper
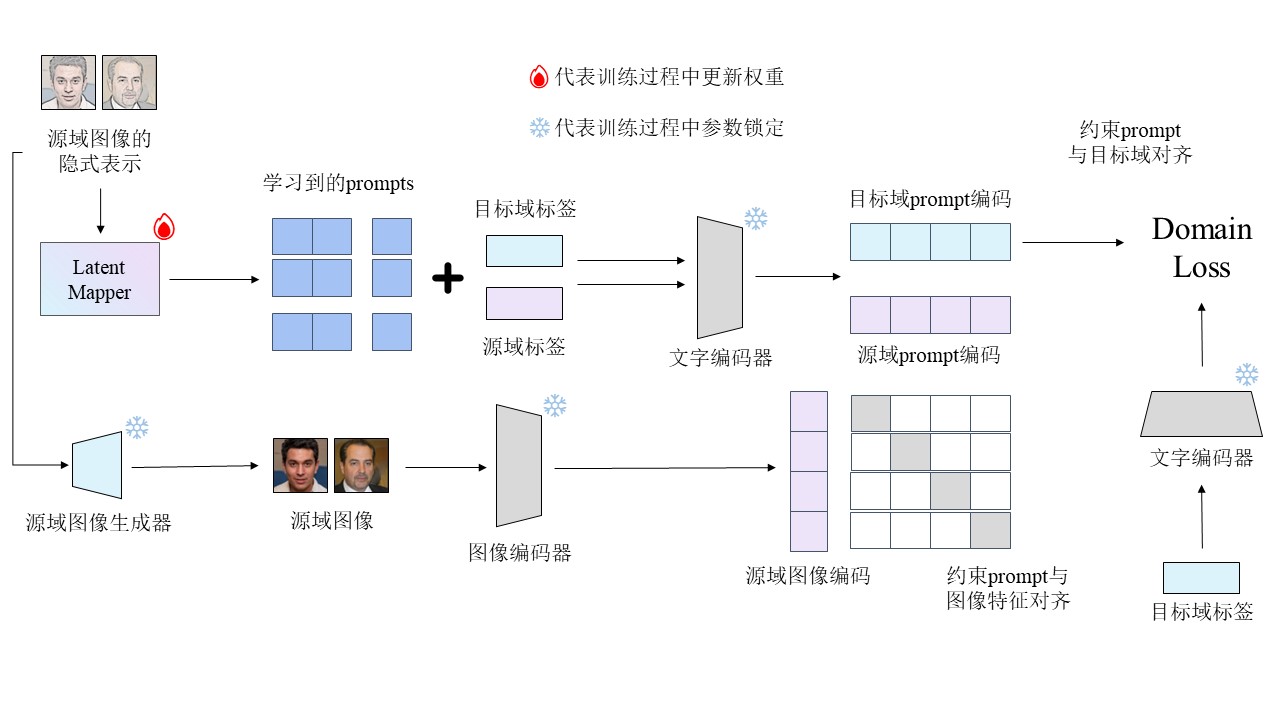
第一阶段的主要任务是训练Lantent Mapper来为每一个训练集的源域图片生成一组prompt。Latent Mapper接收源域图像的latent representation,生成一组prompt向量。第一阶段需要解决两个问题,即在zero-shot的背景下,如何实现prompt与源域图像特征的对齐以及prompt与目标域空间的对齐,因此第一阶段的训练分两部分进行。
第一部分是Latent Mapper输出的prompt与目标域标签concat后送入来自CLIP的Text Encoder得到目标域图片prompt在CLIP空间的编码表示,并与目标域标签经过Text Encoder后的编码共同作为Domain Loss的输入来约束从源域中学习到的prompt与目标域空间对齐。
第二部分是Latent Mapper输出的prompt与源域标签concat后送入来自CLIP的Text Encoder得到源域图片prompt描述在CLIP空间的编码表示,同时源域图像再经过来自CLIP的Image Encoder后得到其在CLIP空间的编码表示。将源域的prompt文字和图像编码表示作为contrastive learning loss的输入,约束学习到的prompt与源域图像的特征对齐。
第二阶段:将Latent Mapper插入目标域生成器的训练过程
第二阶段利用Directional CLIP Loss来训练目标域生成器,使源于生成器向目标域迁移学习。需要输入源域以及目标域图像、源域以及目标域的prompt描述。源域图像的latent representation分别输入至源域生成器和目标域生成器中得到对应的图像,同时指导风格迁移方向的源域以及目标域的prompt描述由Latent Mapper接收源域图像的隐式表示后输出再分别与源域和目标域标签concat而得到。分别将源域图像、生成的目标域图像以及源域、目标域的图片prompt描述一起输入至Directional CLIP Loss,从而约束由源域图像生成器初始化的目标域图像生成器向目标域的迁移学习。