扩散模型(Diffusion Model)
在以前的文章图像生成模型中已经大概介绍了目前SOTA的图像生成模型的共同点,并初步了解了Diffusion Model,在这篇文章中将详细讲解扩散模型的数学原理等。
基本概念
首先回顾一下扩散模型的基本概念和生成过程,可以大概分为两步:
-
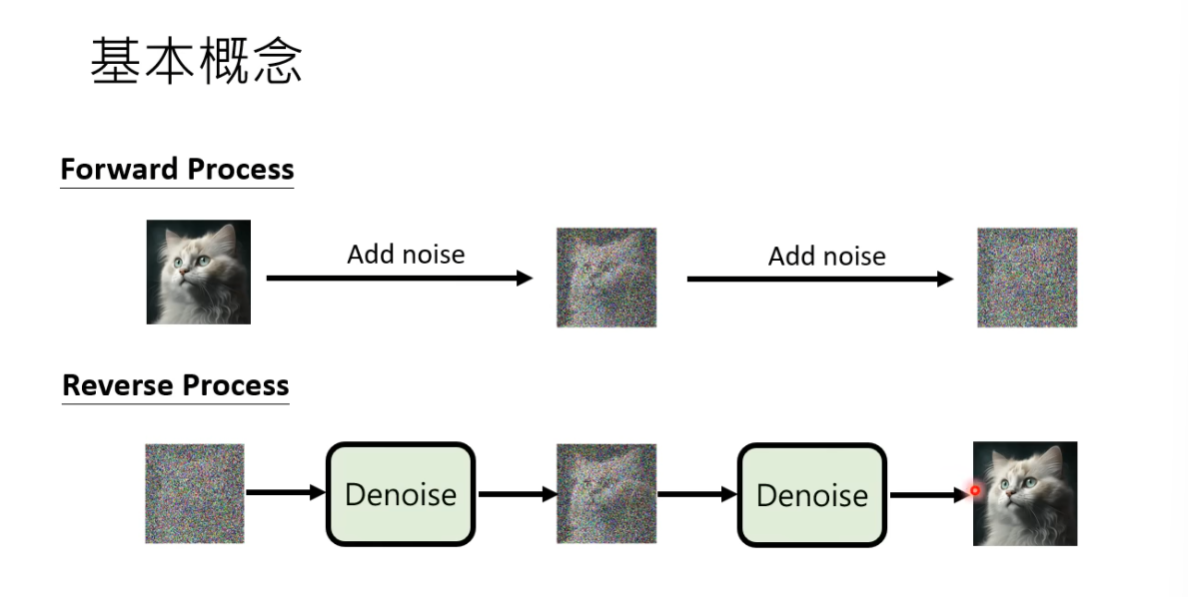
Forward Process:对训练集中的图片不断加入与图片shape相同的、从某随机分布中sample出的噪声,直至图片可以被认为是从该随机分布中sample出的矩阵。
Forward Process又叫做Diffusion Process,在这一步中产生的噪声-加入噪声的图像对可以用来训练Noise Predictor,即从有噪声的图像中预测出其中的噪声,再从输入中减去噪声得到降噪后的图片。
图像生成的原理这一步的目的也同样在之前的文章图像生成模型中提到过:由于根据文字prompt期待生成的图像并不是固定的,可以认为生成的图片在目标域(Target Domain)符合某种分布。因此目前的SOTA模型除了将文字prompt作为输入,还从某随机分布中sample出图片shape的随机向量(矩阵)作为输入,期待模型根据prompt将源域(Source Domain)输入的随机向量映射到目标域的分布,生成对应的图片。
-
Reverse Process:使用Diffusion Process训练的Noise Predictor,根据文字Prompt对从随机分布中sample出的图片大小的噪声图片进行降噪,得到原图。
值得注意的是,变分自编码器(Variational Auto-Encoder, abbr. VAE)与Diffusion Model非常相似:VAE对训练集中的原始图像使用Encoder将其变换为某种Latent Representation,这种Latent Representation的分布也是符合某种随机分布的,VAE再通过Decoder将期待生成的目标域图像还原出来。
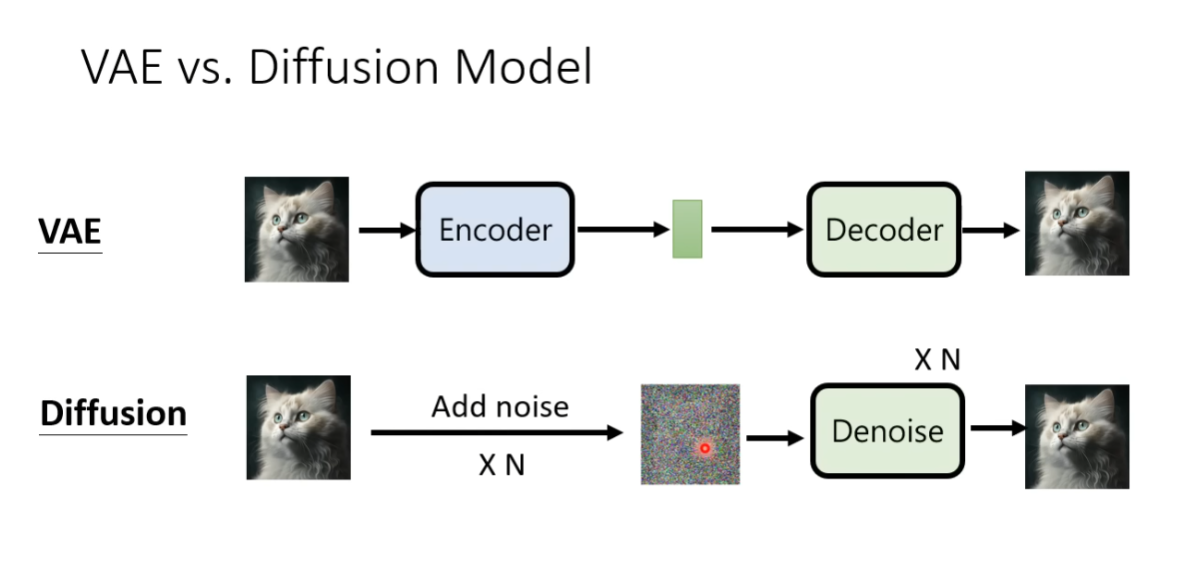
在下面的文章中我们也会学习一下VAE的数学原理,从VAE到Diffusion Model的具体数学推导,可以参考胡老师推荐的论文Understanding Diffusion Models: A Unified Perspective。
下面我们以DDPM论文中的原图来分析DDPM的训练与推理过程。

训练过程
-
循环开始,重复以下步骤;
-
首先从数据集中sample出原始图像;
-
是从范围中sample出的一个integer;
-
是从Normal Distribution中sample出的与相同大小的噪声;
-
根据如下规则进行梯度下降,训练Noise Predictor:
首先对和根据权重做weighted sum产生加入噪声后的图像。通常来说,至是递减的,当在第2步中sample到的越大,则原始图像对新图像的贡献越大。
是Noise Predictor,其输入是加入噪声的图像以及sample出的,而训练的Ground Truth就是第3步中sample出的噪声;
-
直至噪声预测模型训练至收敛。

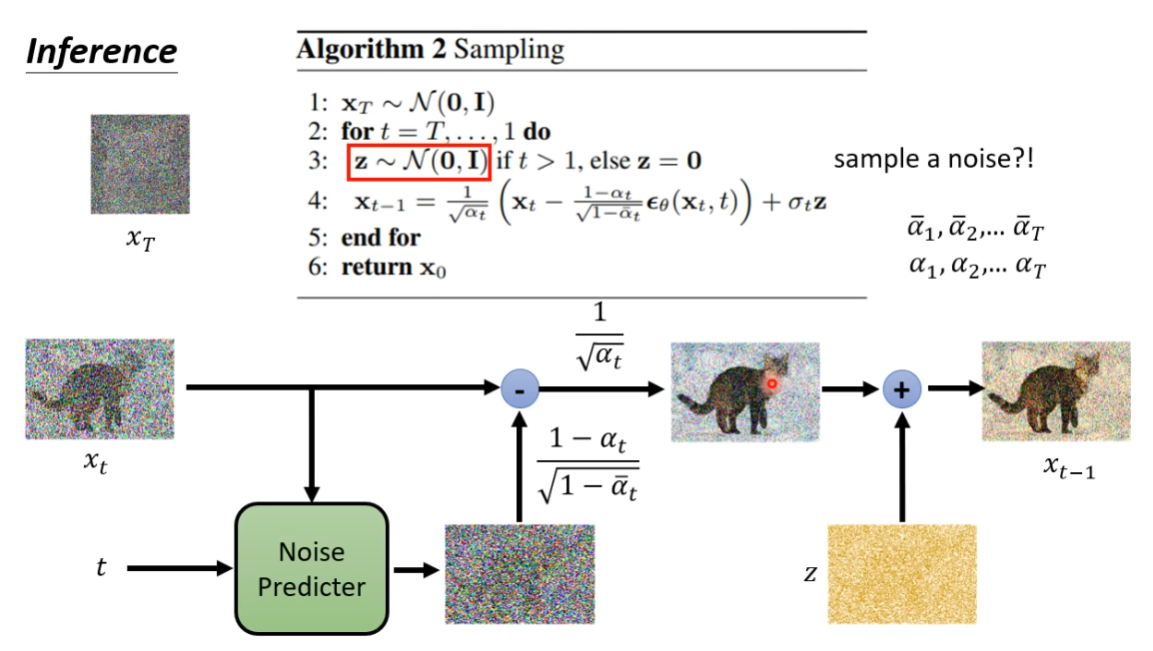
推理过程
-
从Normal Distribution中sample出图片大小的噪声;
-
从范围循环次;
-
对与每一次以计数的循环,若,则从Normal Distribution中sample出,否则;
-
根据如下公式得到降噪后的图像:
其中,代表上一步骤中输出的降噪后的图像,代表当前步骤即将输出的降噪后的图像,代表Noise Predictor预测出的噪声,以及是两组权重序列;
-
结束本次for循环;
-
当时,得到,即最终降噪后的图像。