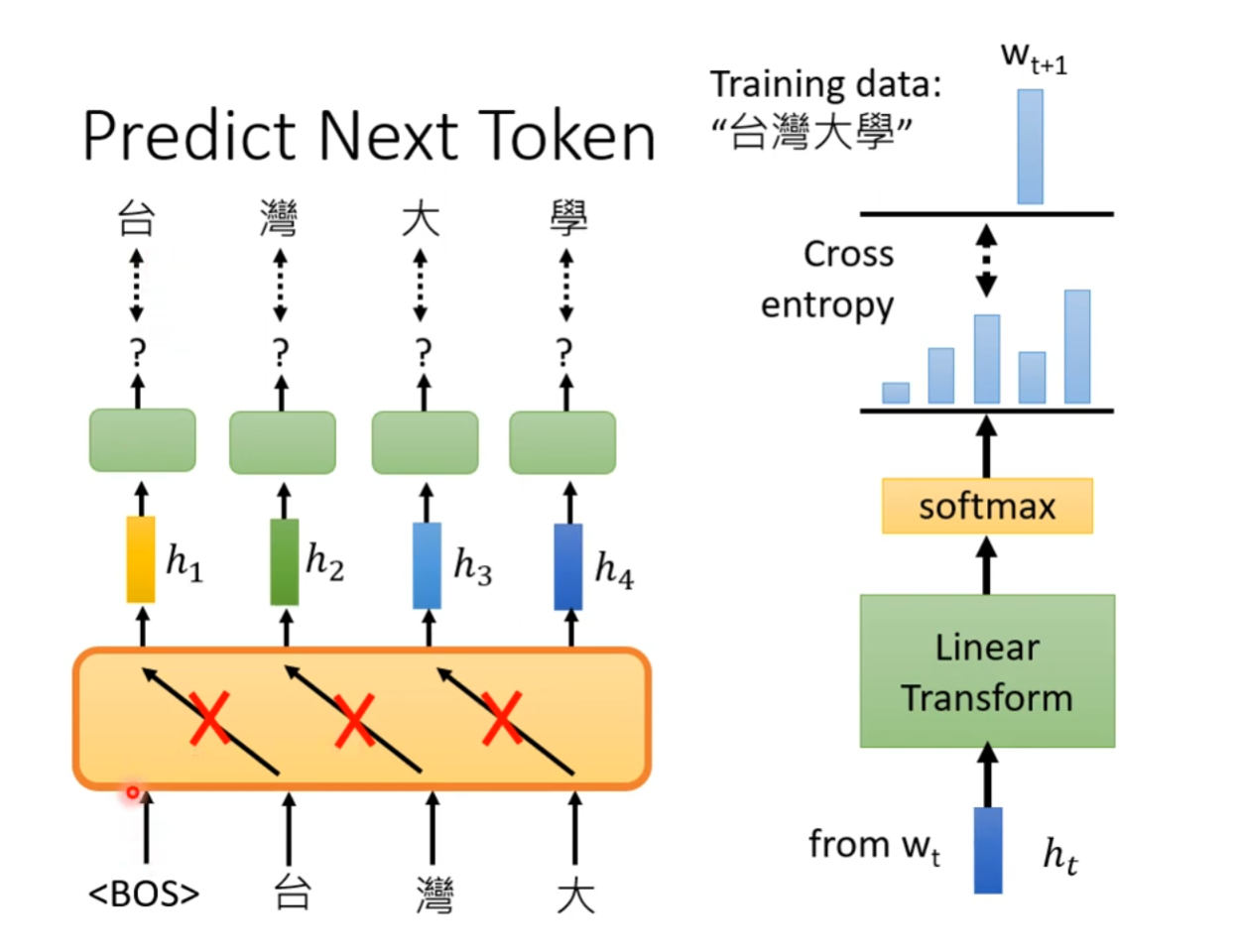
自监督学习(Self-Supervised Learning)
在自监督学习的模型中,出现了很多以芝麻街任务命名的经典模型和论文。
介绍
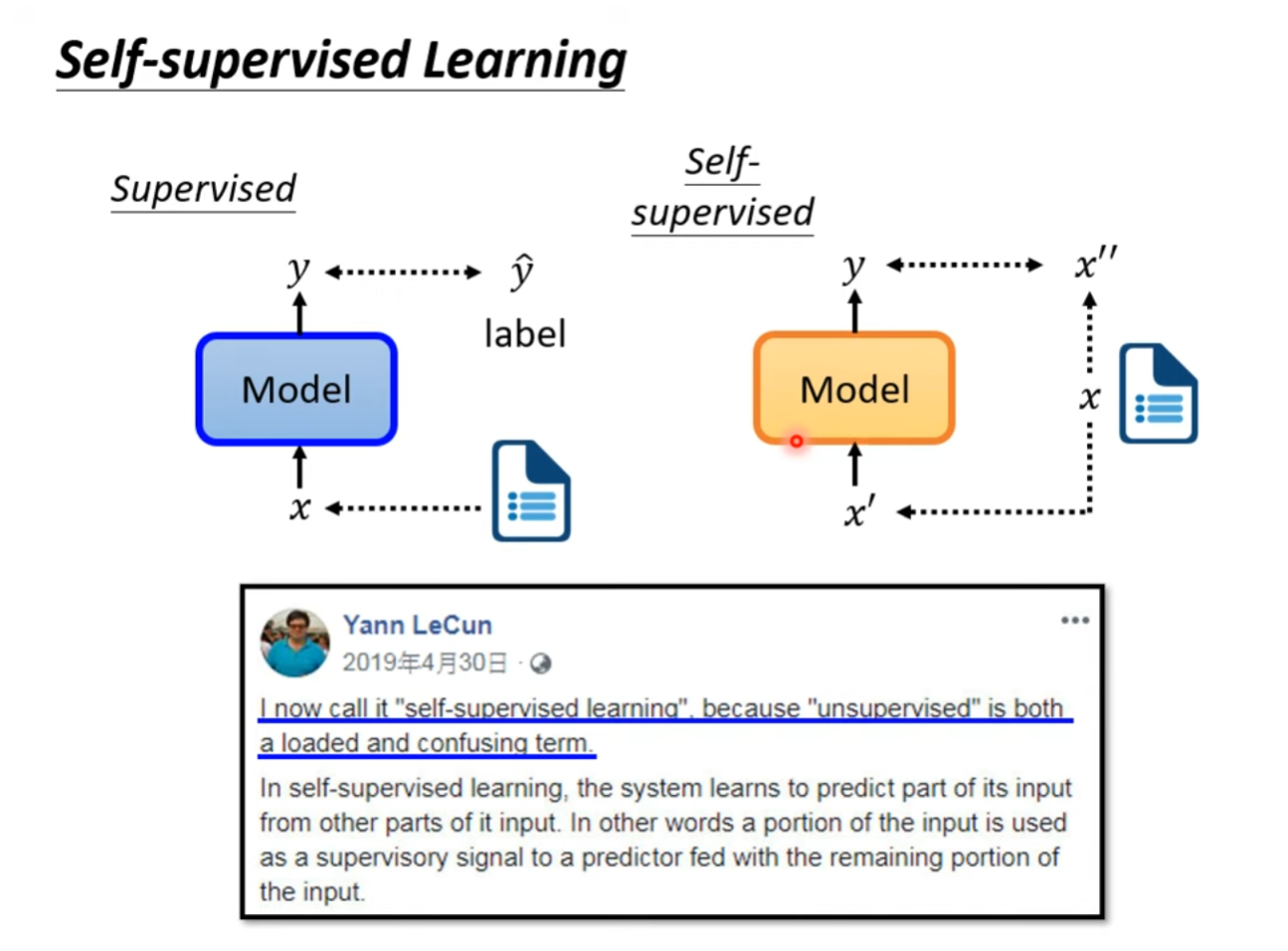
自监督学习是无监督学习的一种方法,利用未标记的数据来训练模型。与传统的监督学习不同,自监督学习不需要依赖人工标注的标签数据,而是通过自动构建任务来生成伪标签,从而指导模型的学习。
自监督学习的基本原理是,通过对输入数据进行某种变换或操作,使得模型能够从中提取有用的特征和语义信息。例如,在自然语言处理领域,一种常见的自监督学习任务是预测下一个单词;在计算机视觉领域,一种常见的自监督学习任务是预测图像中的缺失部分。这些任务可以帮助模型学习到输入数据中的潜在结构和规律,从而提高其泛化能力和性能。
BERT(Bidirectional Encoder Representation from Transformers)
下面以BERT为例,介绍自监督模型。
结构
BERT的结构其实是Transformer的Encoder部分,仅使用Encoder做特征抽取器。
BERT(Bidirectional Encoder Representations from Transformers)本身是一种预训练的模型架构,通常是在大规模无标签数据上进行预训练,然后在特定任务上进行微调。BERT并不是一个用于特定任务的模型,而是一个通用的语言表示模型。
使用 BERT 的一般步骤包括:
- 预训练(Pretraining):在大规模无标签数据上对 BERT 进行预训练,学习通用的语言表示。
- 微调(Fine-tuning):将预训练的 BERT 模型应用于特定任务,并在有标签的数据上进行微调,以适应该任务。
- 应用于下游任务(Downstream Tasks):微调后的 BERT 模型可以被用于执行特定的下游任务,如文本分类、命名实体识别等。
Self-Supervised Pretraining
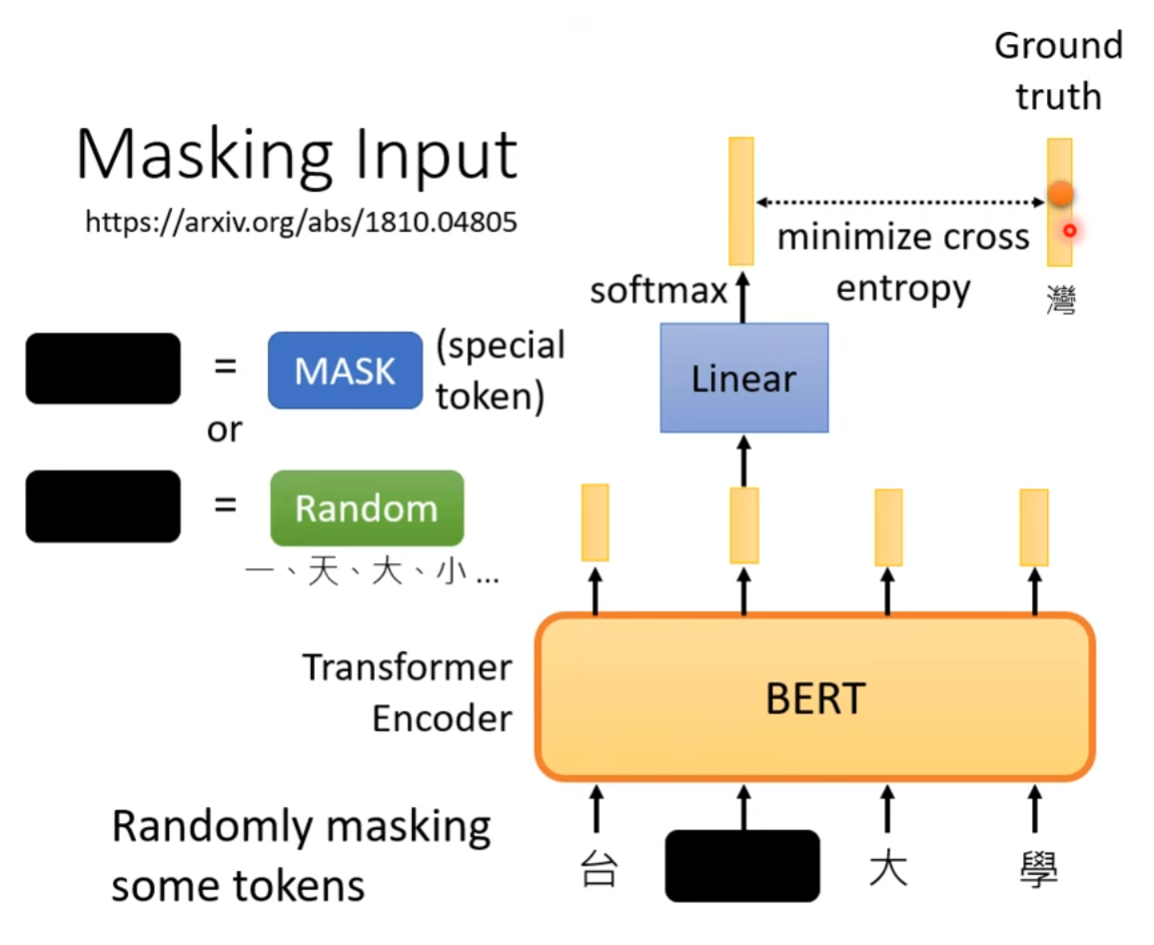
Masking Input
BERT模型的自监督性质主要体现在其训练数据并不需要人为标注label,而是通过对输入句子中的部分词汇做mask,将输入数据的部分内容使用special token或random token进行遮挡后,喂入Encoder中。对于每个被mask掉的词汇,BERT输出一个概率分布向量,表示这个词汇属于词汇表中的哪一个。
BERT的损失函数主要是Masked Language Model(MLM)任务的交叉熵损失,通过最小化Encoder输出的概率分布与Ground Truth之间的交叉熵损失函数来训练模型。
其中:
- 是输出的概率分布向量的维度。
- 是概率分布向量标签。
- 是模型预测的概率分布向量。
Next Sentence Prediction
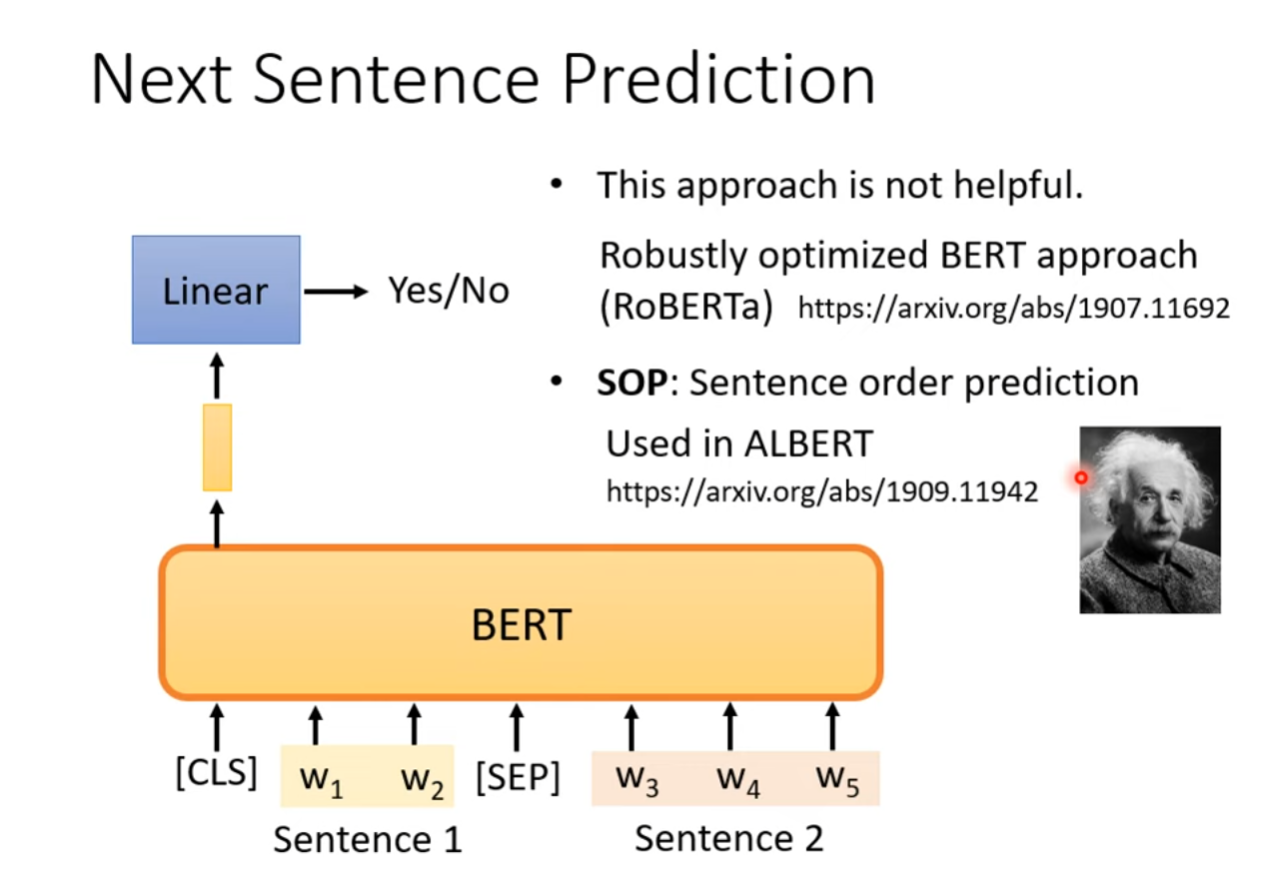
Fine-tuning
在预训练之后,BERT 的模型参数可以被用于多个下游任务,如文本分类、命名实体识别、问答等。
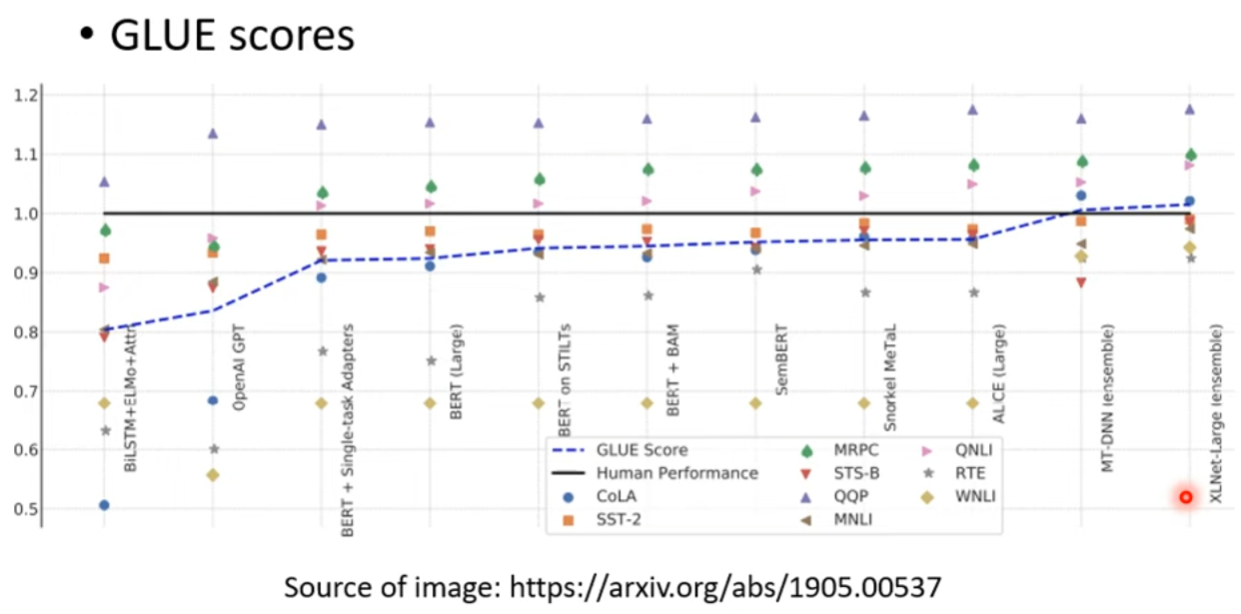
首先,我们先来了解一下NLP任务中很重要的一个Benchmark:GLUE。
Benchmark: GLUE
GLUE(General Language Understanding Evaluation)是一个评估自然语言处理模型在多个任务上综合性能的基准(benchmark)。它旨在测试模型对各种语言任务的通用理解能力。GLUE benchmark 包含了多个任务,每个任务都有一个对应的数据集和评估标准。
- MNLI(MultiNLI):自然语言推理任务,要求模型判断给定的两个句子之间的关系是蕴含、矛盾还是中立。
- QQP(Quora Question Pairs):问题匹配任务,要求模型判断两个问题是否语义上等价。
- QNLI(Question-answering Natural Language Inference):句子分类任务,要求模型判断给定问题和句子之间的关系。
- RTE(Recognizing Textual Entailment):文本蕴涵任务,要求模型判断给定的两个文本之间是否存在蕴涵关系。
- STS-B(Semantic Textual Similarity Benchmark):语义文本相似度任务,要求模型度量两个文本之间的语义相似度。
- CoLA(Corpus of Linguistic Acceptability):语言可接受性判断任务,要求模型判断一个句子是否语法上正确。
- MRPC(Microsoft Research Paraphrase Corpus):短语匹配任务,要求模型判断两个句子是否语义上等价。
- SST-2(Stanford Sentiment Treebank):情感分类任务,要求模型判断给定句子的情感极性。
- WNLI(Winograd NLI):自然语言推理任务,属于 Winograd 模式的变体,要求模型判断一个给定的句子对是否存在蕴含关系。
GLUE 提供了一个全面的测试平台,有助于评估和比较不同自然语言处理模型在多个任务上的性能。
Downstream Tasks
Sentiment Analysis
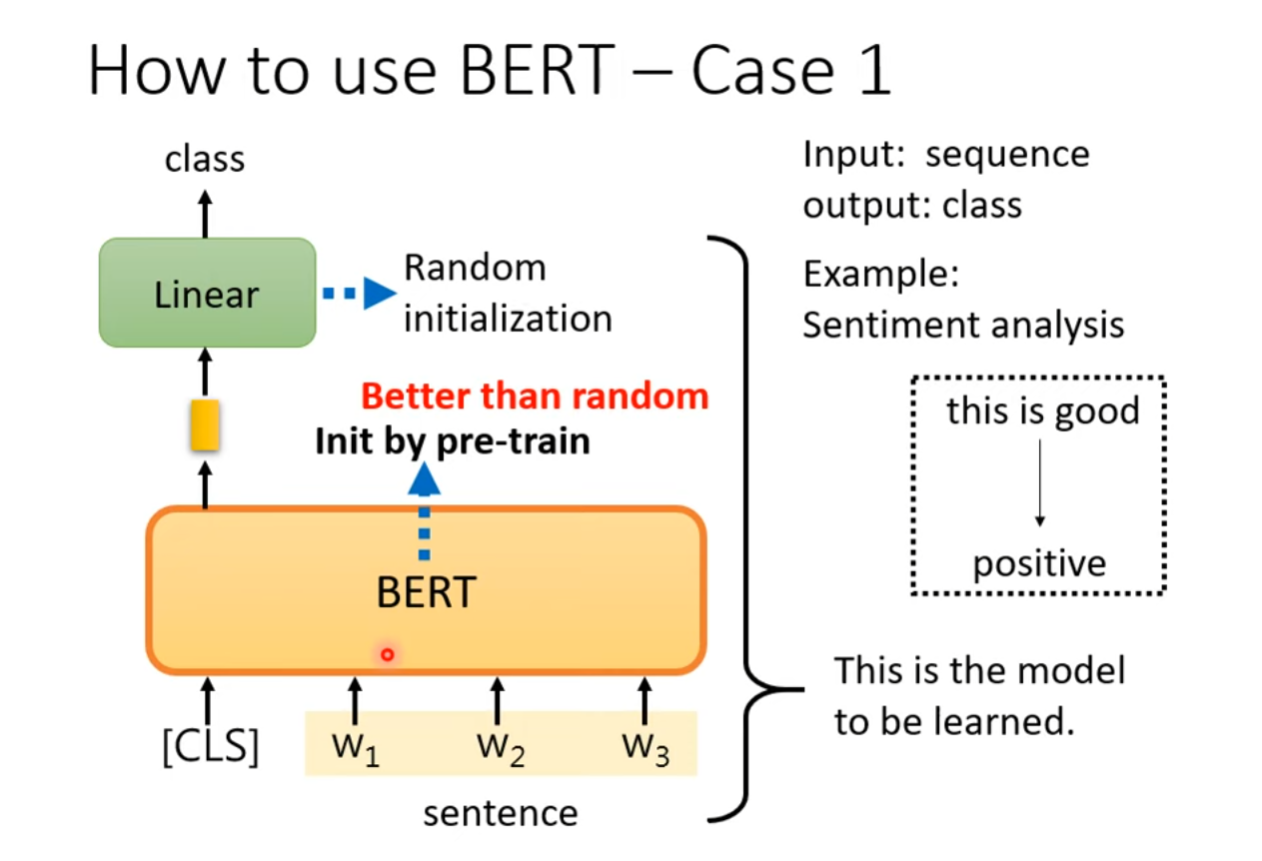
BERT作为自监督的预训练模型,从大语料库中学习到了一定的语言知识,在做文字情感分析时,只需要在下游连接上对应的分类器网络,即使只有比较少量的训练资料也能得到比较好的效果。
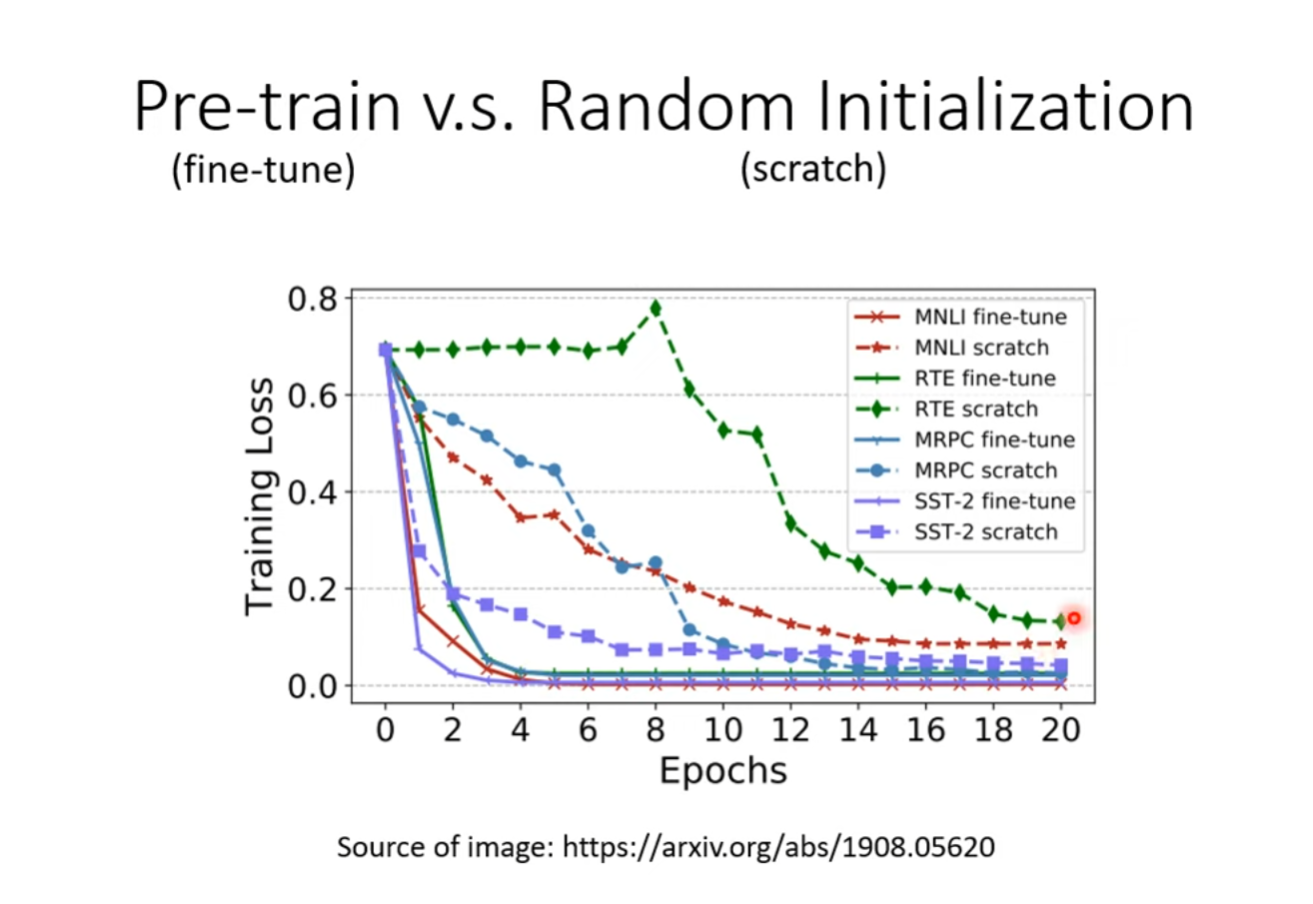
下图将Pre-training&Fine-tuning范式与Scratch范式的训练效果做了对比,其中Scratch范式即使用传统的随机初始化的方式从头训练整个分类网络。可以看到预训练&微调的训练范式可以加速模型的收敛(Convergence)并且效果也更好。
立场分析
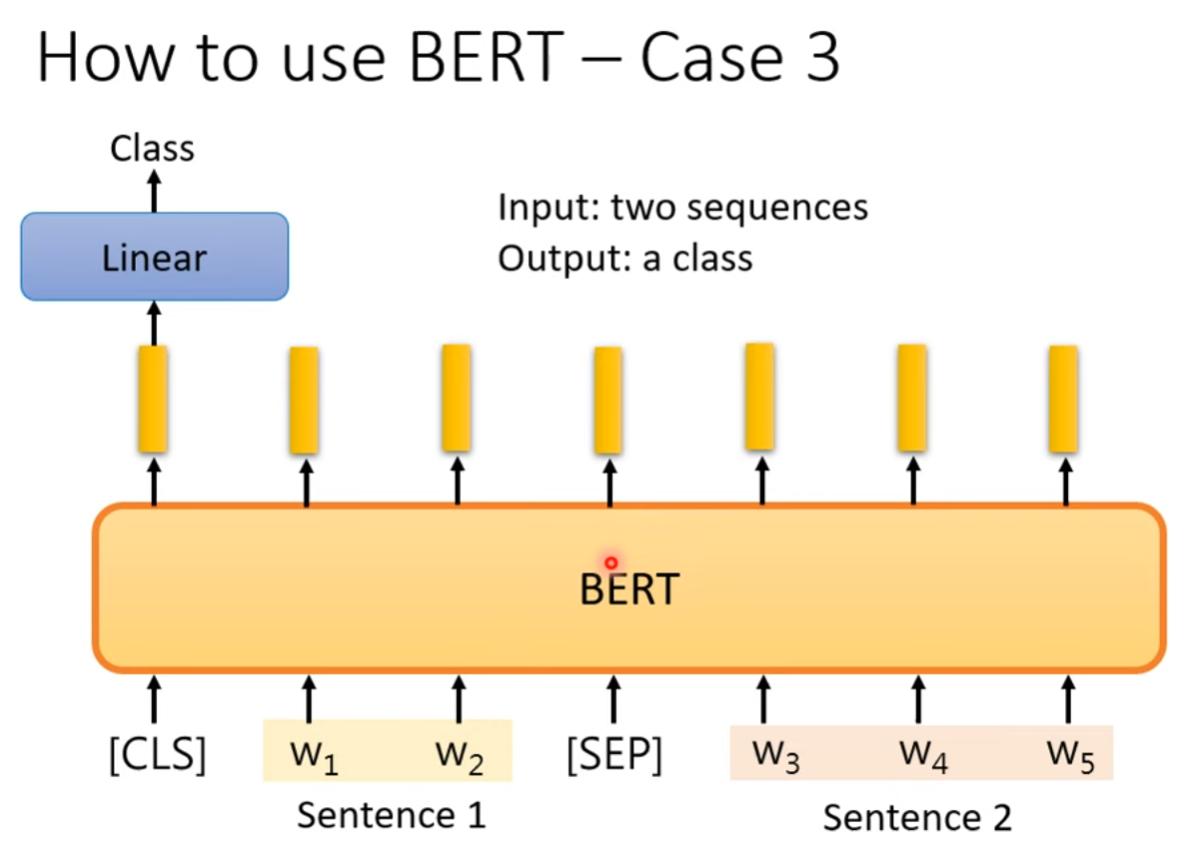
Extraction-based Question Answering
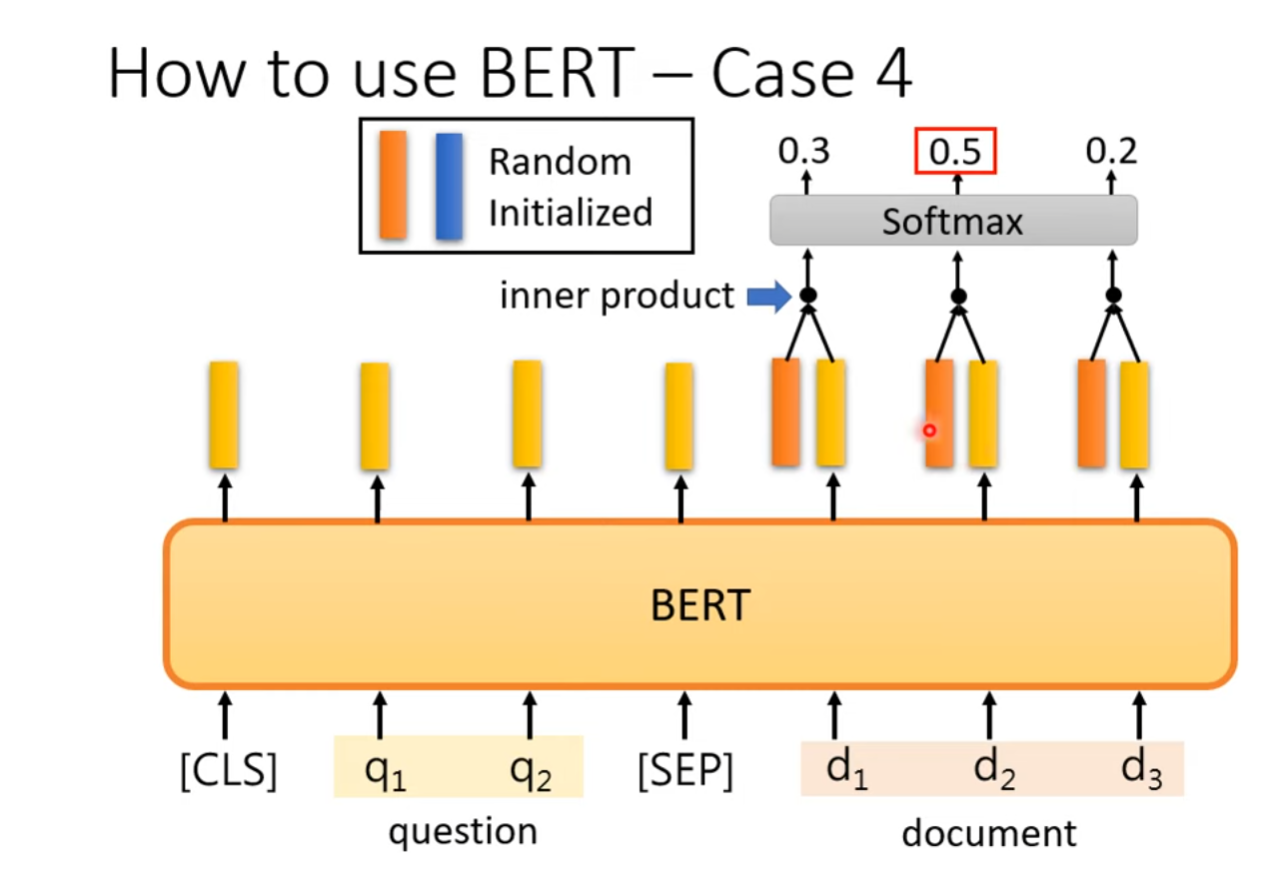
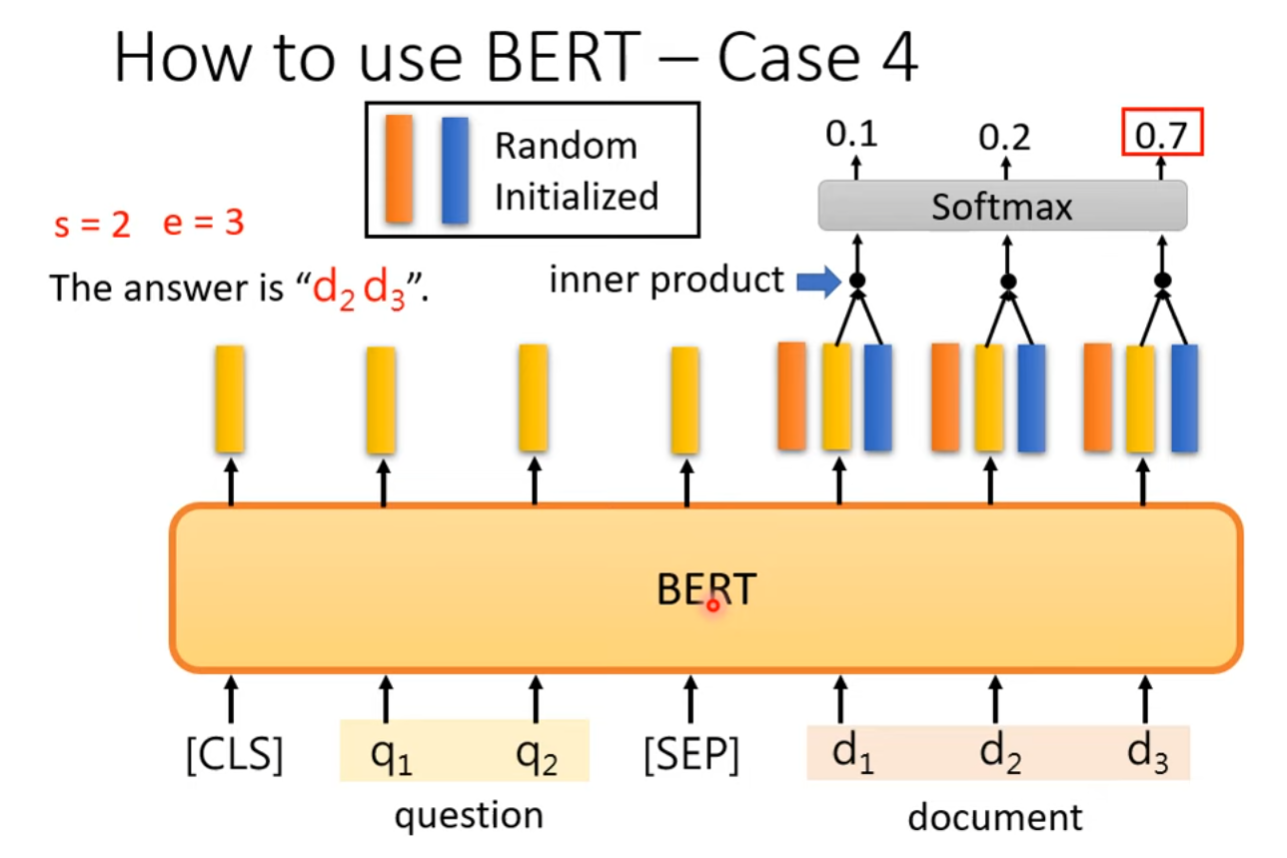
BERT也可以用来完成截取式问答任务,提供一篇文章以及问题,要求输出两个integer代表答案短语在该文章中的起始位置以及结束位置。

具体的解决方案:选择输入文章的所有token所对应的输出向量,随机初始化两个相同维度的向量,分别与输出向量做Dot Product,在经过Softmax之后选择最大的得分所对应的索引。得到的两个索引分别是答案短语在文章中开始的位置以及结束的位置。
其他应用
虽然以上的应用都是NLP领域的,但是BERT是Seq2Seq模型,图片、语音等信号也都可以作为Sequence输入至BERT中,因此BERT也可以通过迁移学习应用至多模态领域。
Why does BERT work?
BERT在大规模语料库(Corpus)上预训练后,输出的向量表示了对应输入token的意思,特别地,是考虑了上下文信息的意思。比�如,对于水果的苹果已经苹果公司的苹果,BERT对一样的苹果有不同的输出。即对一个处在不同上下文信息中的相同词汇,BERT有不同的Embedding。类似于Word Embedding中的CBOW,BERT可以看作是Contextualized Word Embedding。
BERT模型的核心就是通过预训练来学习上下文信息,进而对每个输入token生成相应的向量表示。这个向量表示考虑了上下文信息,所以对于处在不同上下文中的相同词汇,BERT会有不同的Embedding。
——来自讯飞星火大模型
虽然 BERT 的确是一种基于大规模语料库的预训练模型,但它并不是一种简单的词嵌入方法,而是一种深度神经网络模型。
在 BERT 中,每个单词都被嵌入到一个高维空间中,并且这些嵌入向量是通过多层 Transformer 编码器生成的。这些编码器的每一层都包含多个自注意力子层和一个前馈神经网络子层,它们共同作用来捕捉文本中的上下文关系和其他语义特征。
因此,BERT 中的嵌入向量不仅仅是单个单词的词义表征,还包括整个句子或段落中的语境信息。这意味着即使两个单词在不同的上下文中出现,它们的嵌入向量也可能非常相似,因为它们共享相同的语义结构。
总之,BERT 可以被视为一种上下文感知词嵌入技术,但它的实现方式比传统的词嵌入方法要复杂得多。
——来自腾讯混元大模型
GPT: Generative Pre-trained Transformer
GPT的结构是Transformer的Decoder部分,可以承担生��成的任务。
GPT的自监督学习的特征体现在:在训练过程中,GPT根据输入的token预测输入的下一个token应该是什么,对输出的distribution与Ground Truth做Cross Entropy Loss来更新参数。