编译原理笔记
第一章:前言

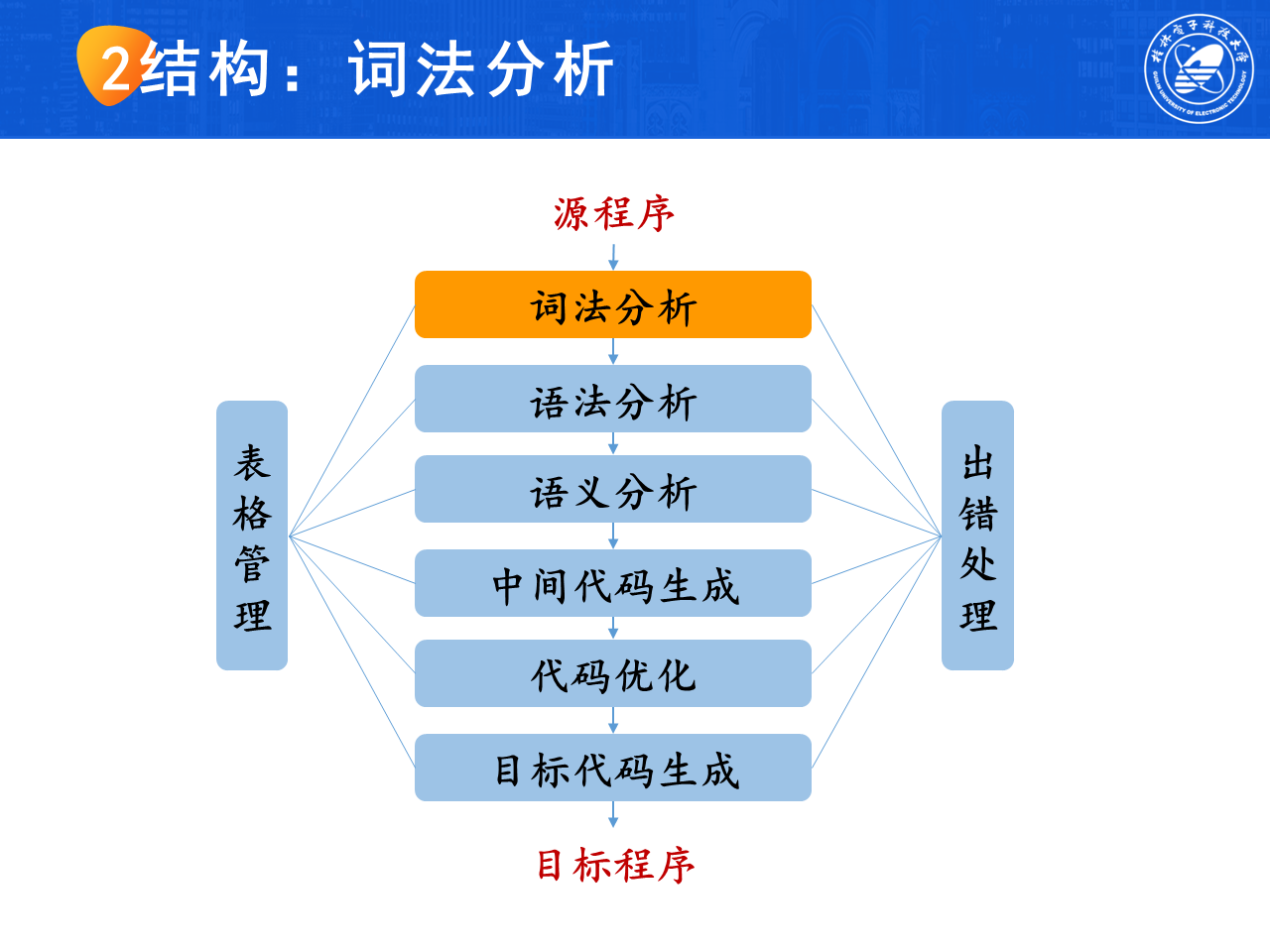
1.1 编译程序的逻辑结构
- 词法分析:分析输入串如何构成句子,得到单词序列
- 语法分析:分析单词序列如何构成程序,构造语法分析树
- 语义分析:审查语义错误,为代码生成收集类型信息
- 中间代码生成
- 代码优化
- 目标代码生成
- 表管理、错误检查和处理贯穿整个过程
1.2 前端和后端
-
前端是指与源语言有关、与目标机无关的部分
如词法分析、语法分析、语义分析、中间代码生成、代码优化中与机器无关的部分
-
后端是指与目标机有关的部分
如代码优化中与机器有关的部分、目标代码的生成
1.3 遍的概念
遍是指从头到尾扫描一遍源程序
第二章:文法和语言
2.1 句型
若从文法的开始符号开始存在以下推导,则称为该文法的一个句型,句型中既可以包含终结符,也可以包含非终结符,也可以是空串
2.2 句子:
则称是该文法的句子
2.3 文法的分类:
-
0型文法,又称无限制文法、短语文法
-
1型文法,又称文有关文法
-
2型文法,又称上下文无关文法(Context-Free Grammar,CFG)
可用来构建语法树,语法树是上下文无关文法推导和规约的图形化表示
-
3型文法,又称正规文法(Regular Grammar,RG)
- 左线性文法
- 右线性文法

2.4 最左/右推导:
如果在推导的任何一步都是对产生式左部中的最左/右非终结符进行替换,则称为最左/右推导,其中最右推导也被成为规范推导
第三章:词法分析
3.1 正规文法转换成��正规式

3.2 有穷自动机(FA)

-
确定的有穷自动机(DFA)
-
DFA的定义及组成

-
确定的含义:在状态转换的每一步,FA根据当前的状态及扫描的输入字符,便能唯一地知道FA的下一状态。
tip在状态转换图中的直观体现就是,在确定行表示的当前状态以及列确定的路径后,得到的目的状态不会是元素个数大于1的集合。
-
DFA的可接受以及接受集的定义:从开始状态开始,经过该符号串表示的路径,若能到达终态则称该符号串可被改DFA接受。

-
-
不确定的有穷自动机(NFA)
-
NFA的确定化,即将NFA转换为DFA(子集法)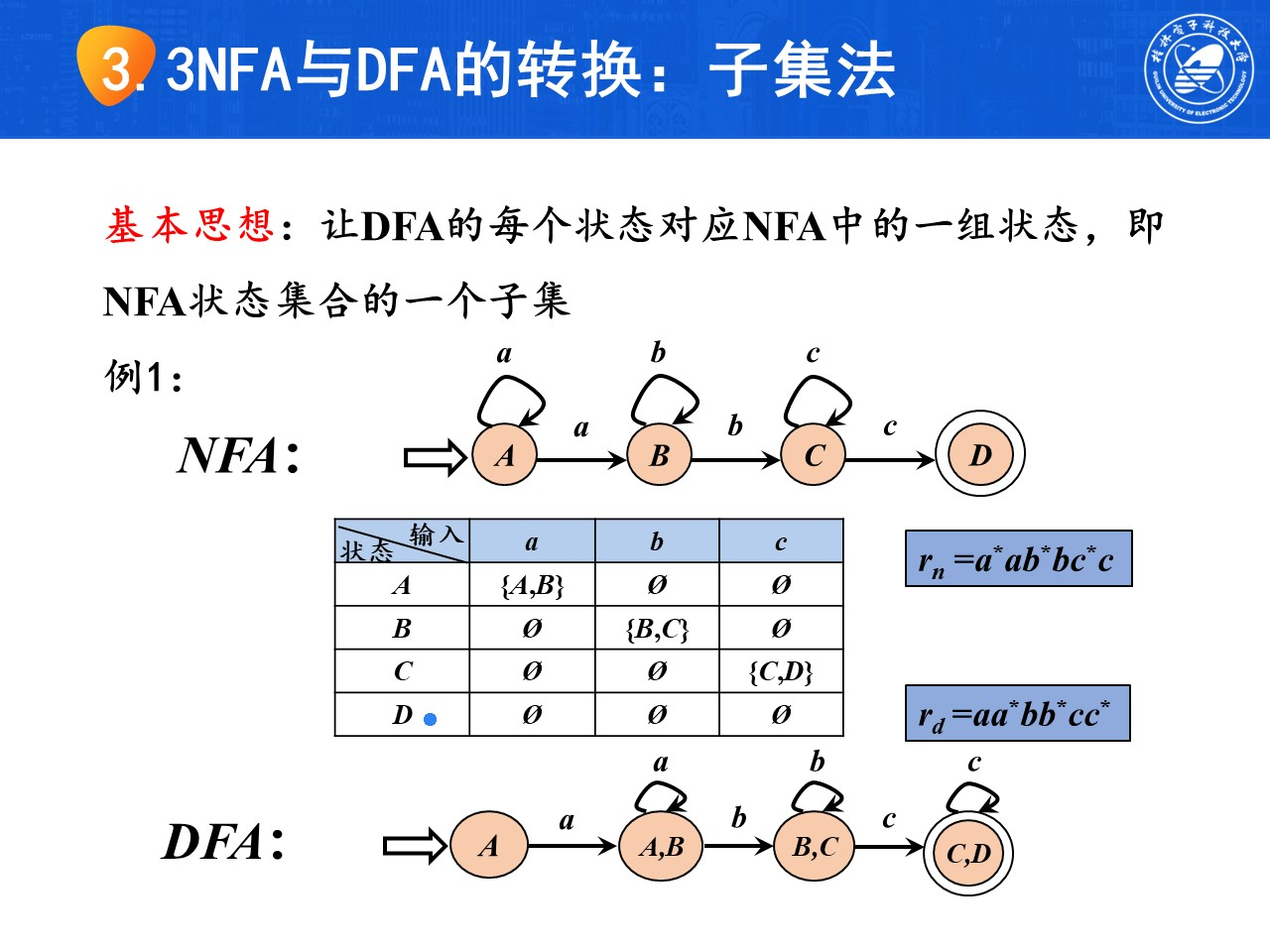
步骤:
-
画出DFA转换表
tip转换表中在状态一列中,状态包含原NFA终态的集合要标*,代表其为等价DFA的终态
- 计算
- 计算
-
为转换表中的状态重命名
-
确定初态和终态
-
-
DFA的最小化(分割法)步骤如下:
 tip
tip考试时注意过程怎么写,下面使用需要三轮分割的列子演示步骤
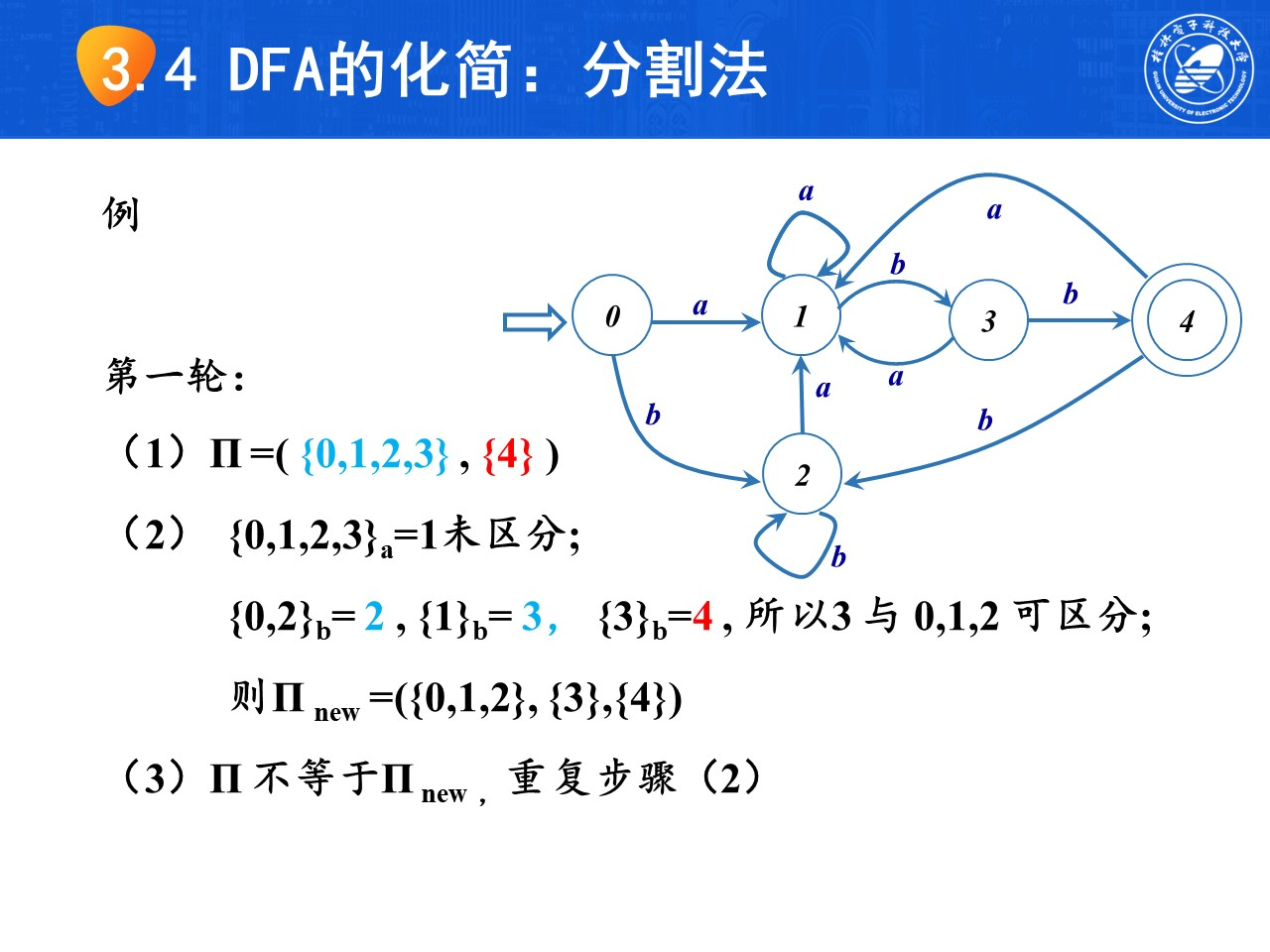
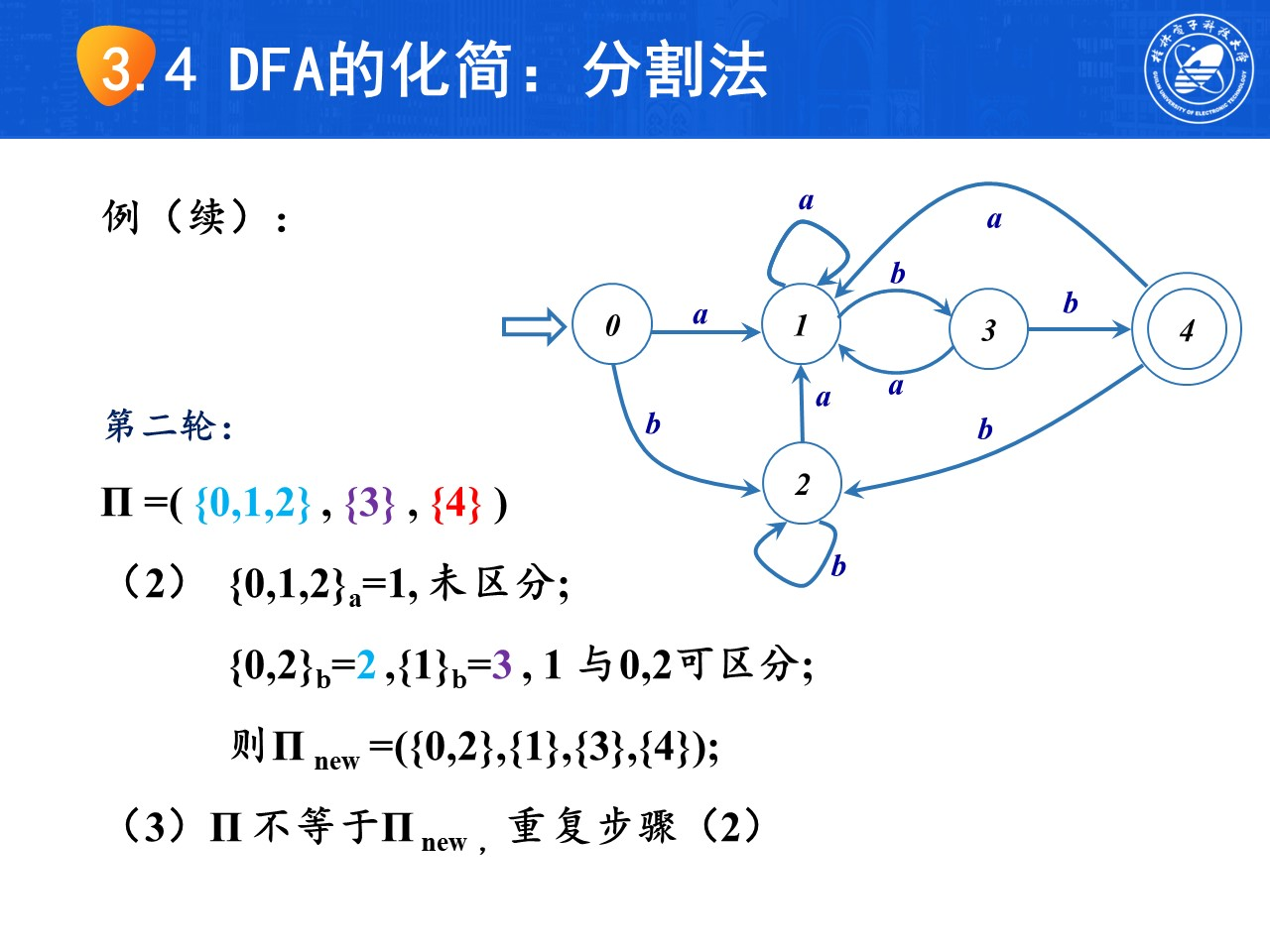
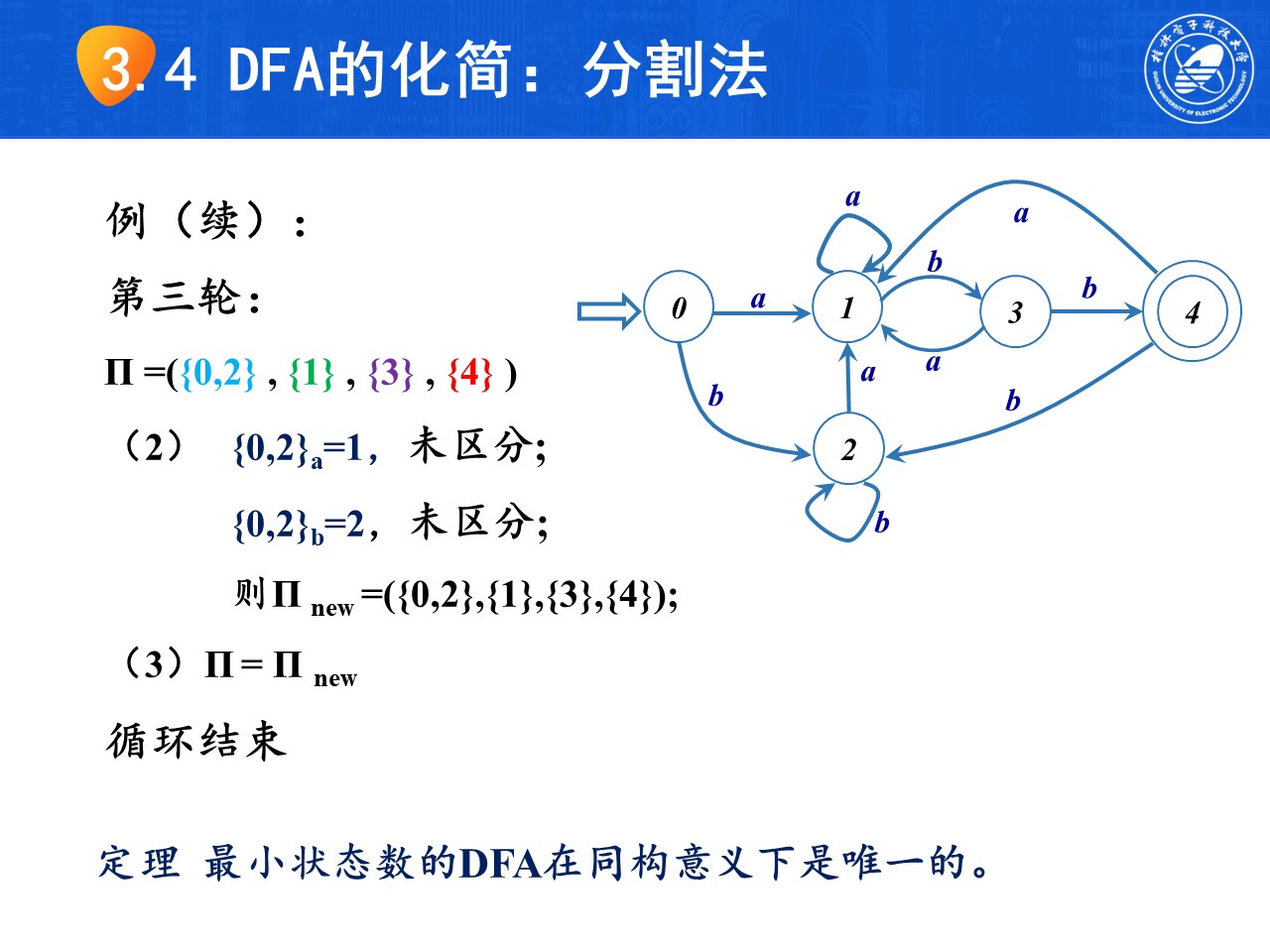
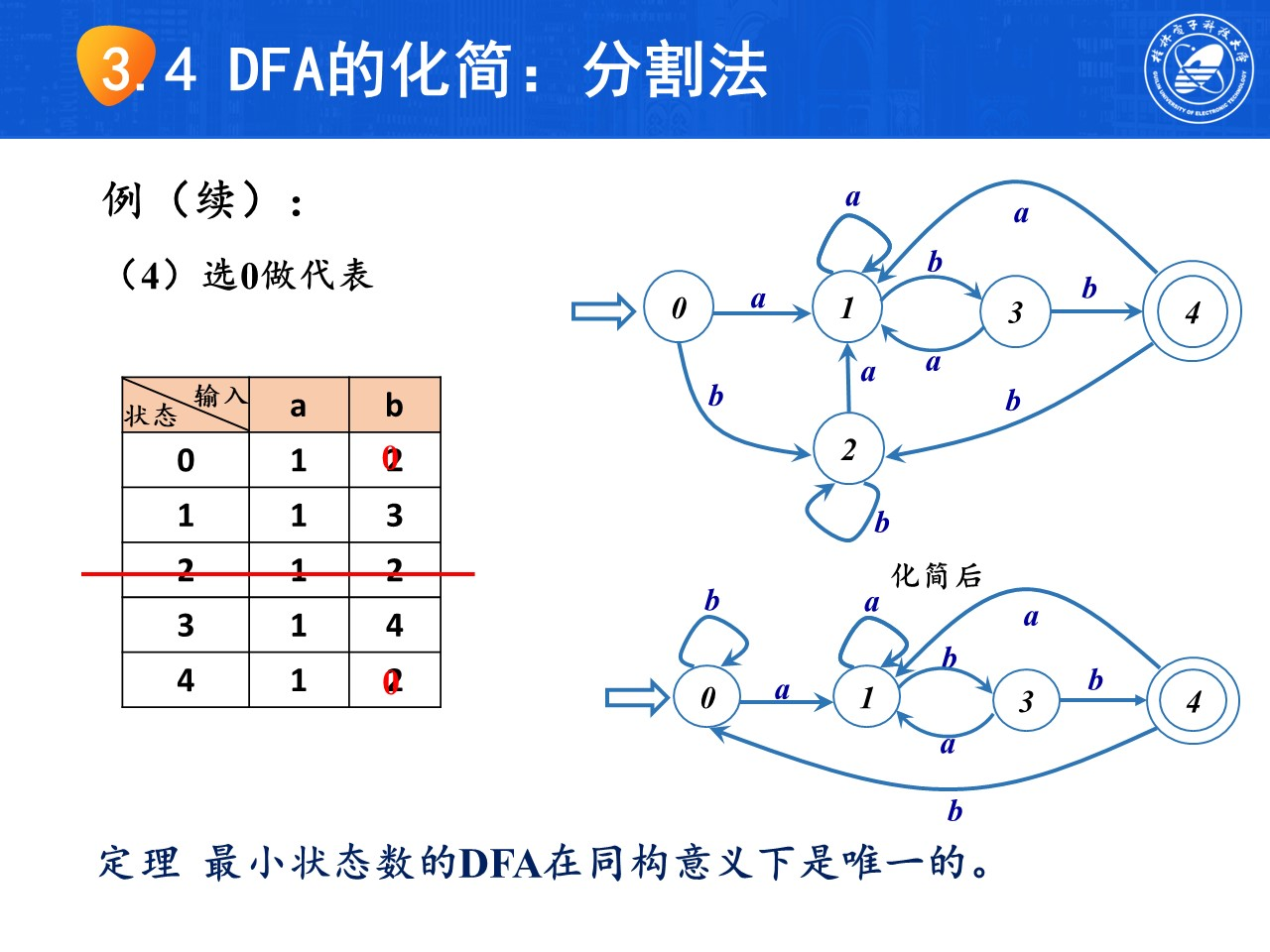
在分割完成后,对可以化简的集合选出一个状态作为代表,删除其他多余状态,重新画图
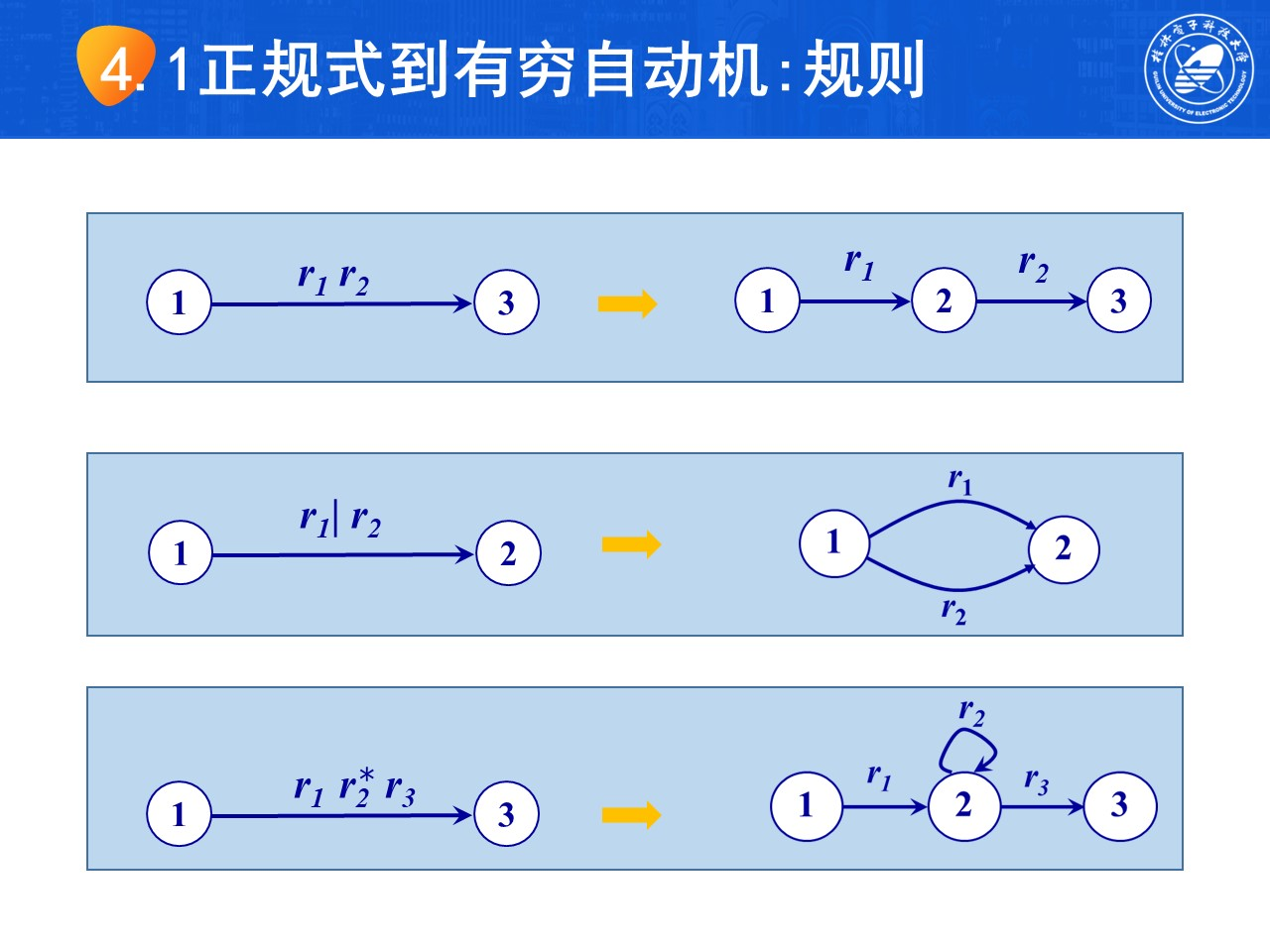
3.3 正规式RE与有穷自动机FA的互相转化
3.4 正规文法RM与有穷自动机FA的互相转化

第四章:自顶向下语法分析方法
描述程序语法结构的规则可以使用2型文法(上下文无关语法,CFG)
语法分析方法包含确定的和不确定的分析方法,确定的语法分析方法根据输入符号,唯一选择产生式
确定的自顶向下分析方法:根据当前的输入符号唯一地确定选用哪个产生式替换相应的非终结符以往下推导
1. FIRST集的定义

2. Follow集的定义

FOLLOW集的求法可以按照下图技巧进行
- 若要求的非终结符是开始符号,则直接将#插入FOLLOW集中
- 在所有产生式的右部中找到要求的非终结符
- 看非终结符的右侧是什么元素
若无元素,则直接将该产生式左部的FOLLOW集加入到该非终结符的FOLLOW集中- 若为终结符,直接将该终结符加入到FOLLOW集中
- 若为非终结符,将FIRST(该非终结符)减去的所有终结符元素都加入至FOLLOW集中

3. SELECT集的定义
需要注意的是FIRST集、FOLLOW集是针对于符号串而言的,而SELECT集是针对于产生式而言的

4. LL(1)文法的定义

5. LL(1)文法的判别

考试时注意书写过程,需要画出以下两张表
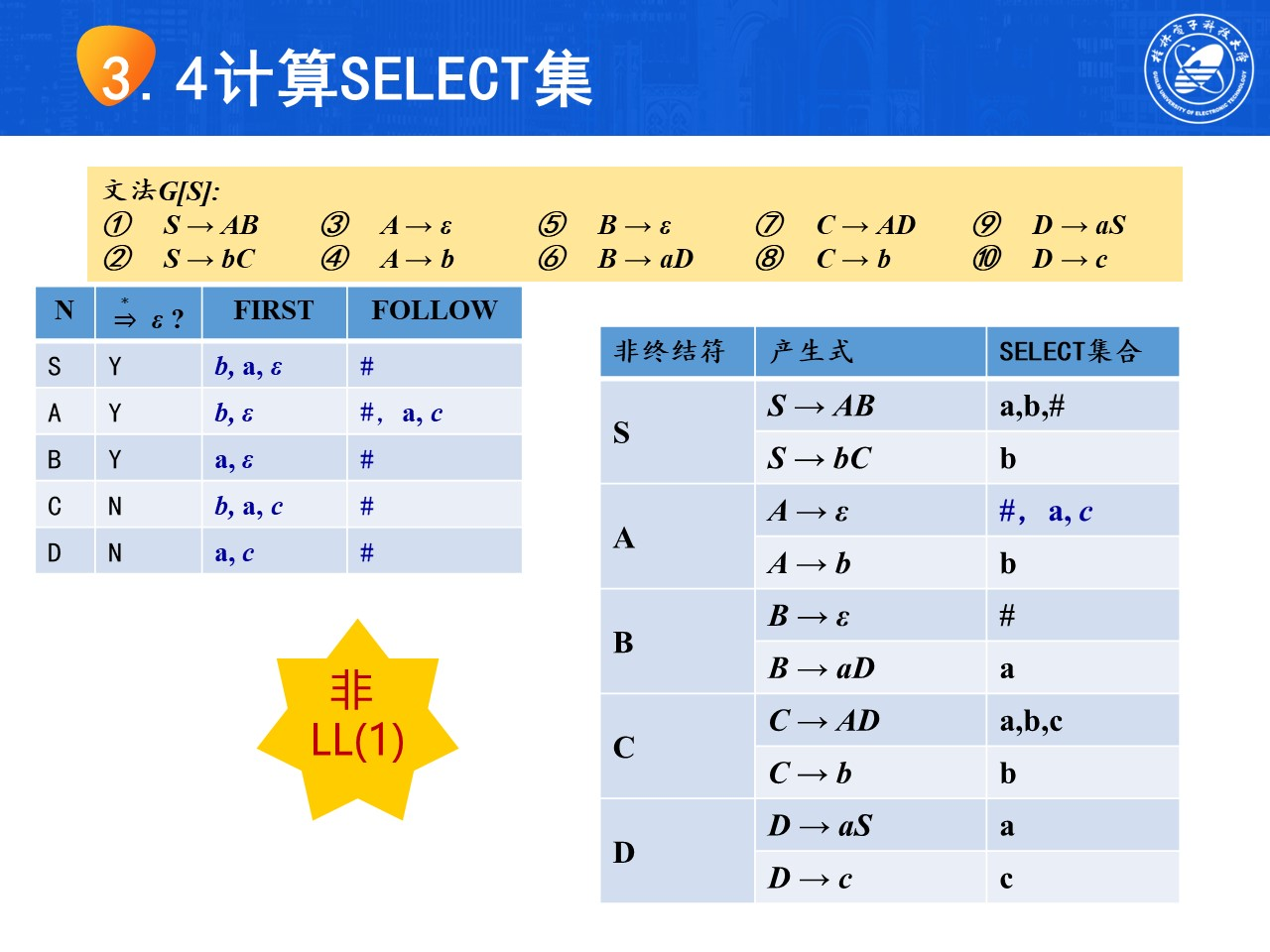
6. 预测分析表
预测分析表通过计算SELECT集得到,形如下表
行标为各非终结符,列标为输入符号,若从某一非终结符开始的产生式的SELECT集包含某一输入符号,则对应产生式就是行列确定的元素值。
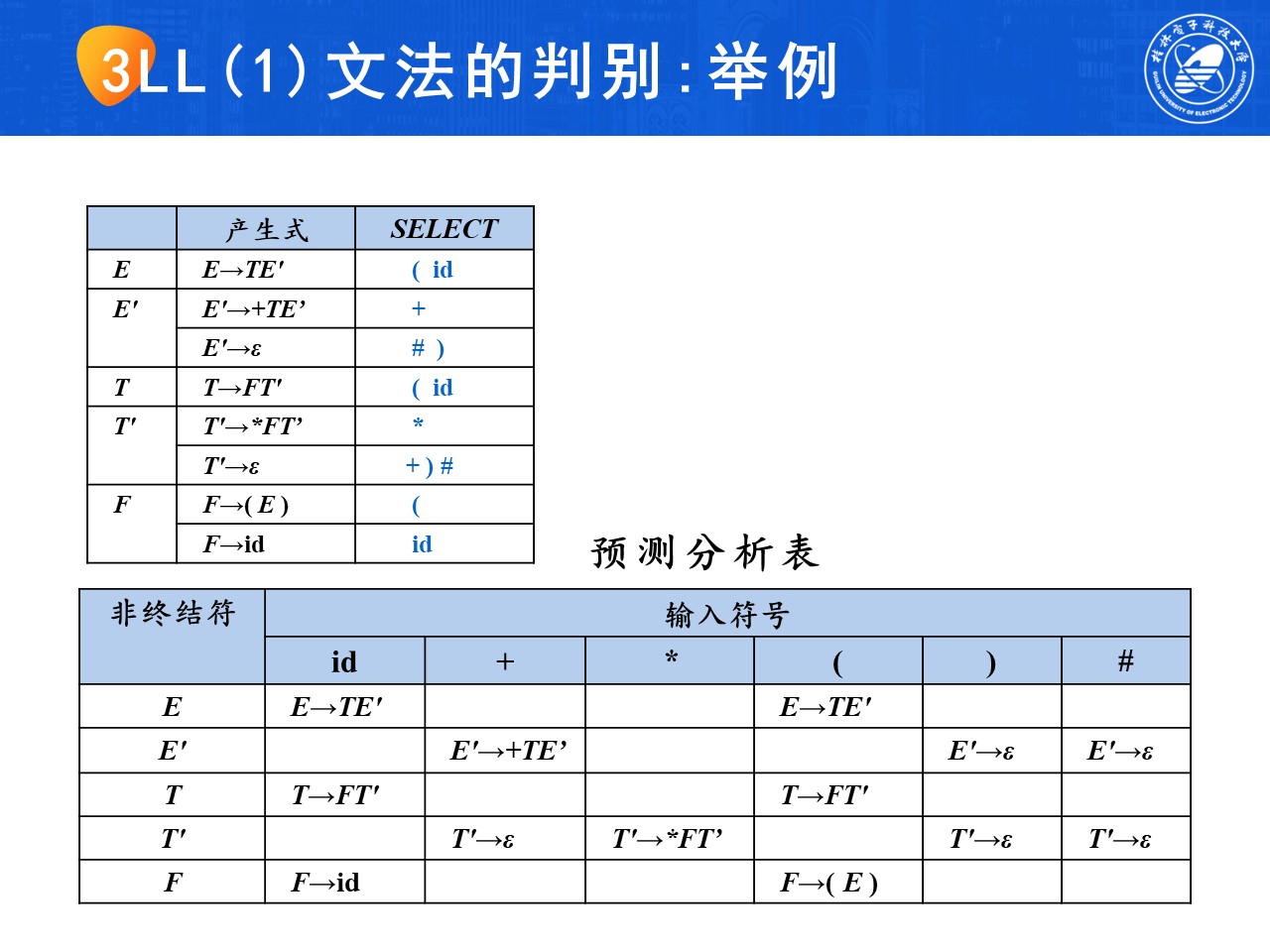
7. 非LL(1)文法到LL(1)文法的等价变换
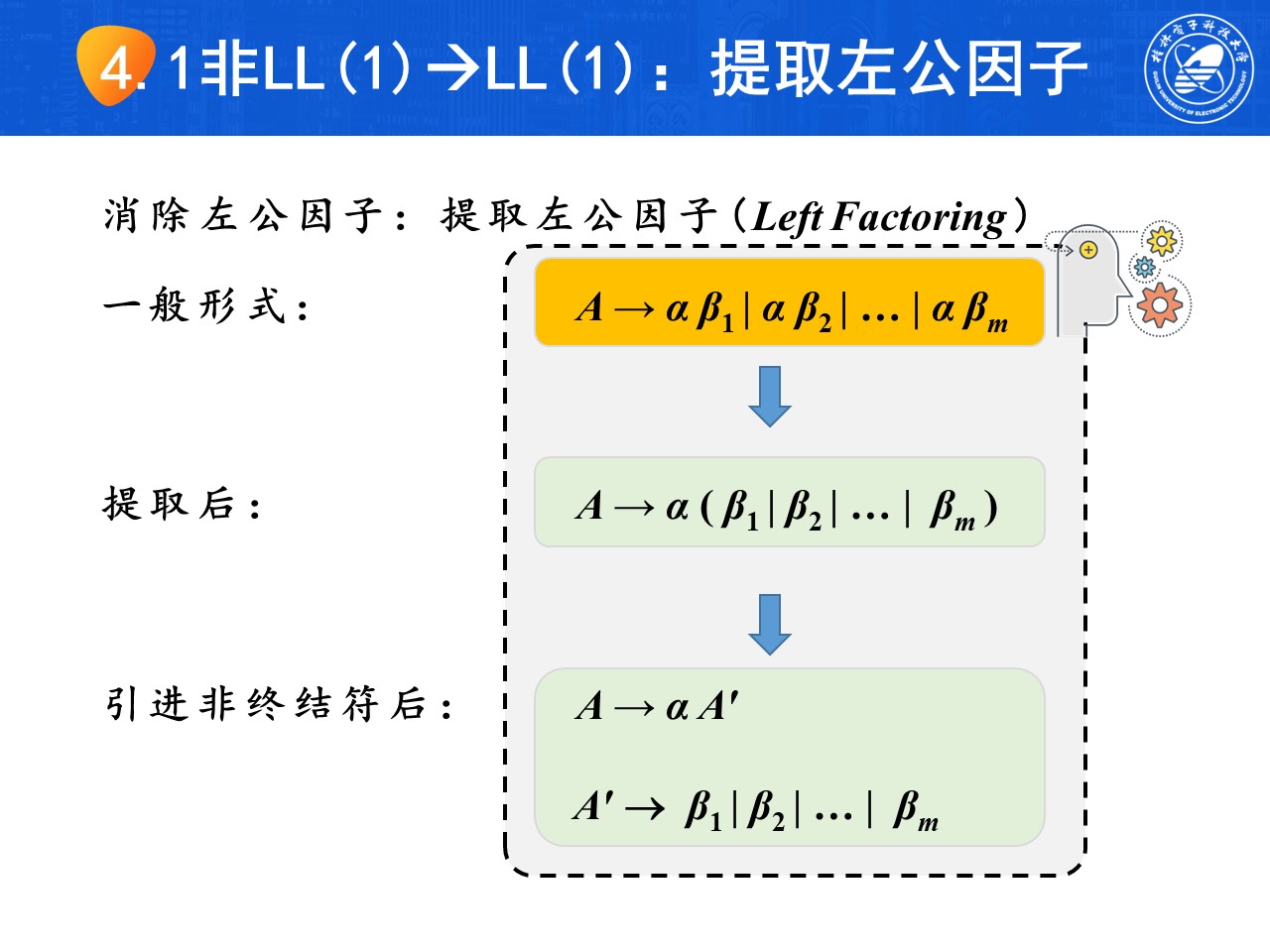
-
消除左公因子(回溯)
caution同一非终结符的多个产生式存在共同前缀,会导致回溯现象,需要消除
-
消除左递归
caution左递归文法会使递归下降分析器陷入无限循环
-
消除直接左递归

-
消除间接左递归
通过代入法变成直接左递归再消除
-
第五章:自底向上语法分析方法
5.1 概念
从的底部向顶部的方向构造语法分析树,采用最左归约的方式,即最右推导的逆过程
注意辨别:自顶向下的语法分析采用最左推导的方式
最右推导是规范推导,最左归约是最右推导的逆过程,又称规范归约
5.2 方法
-
算符优先分析法
按照算符的优先关系和结合性质进行语法分析
-
LR分析法(重点)
规范规约:句柄作为可归约串
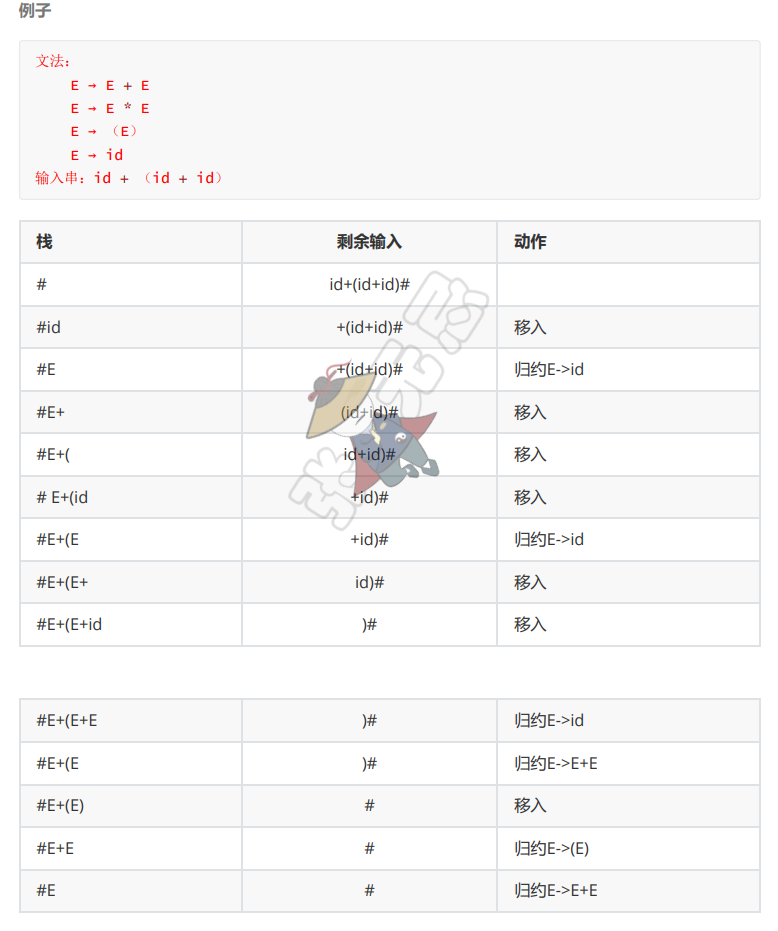
5.3 工作过程

5.4 移入-归约分析器的4种动作
- 移入:将下一个输入符号移到栈顶
- 归约:被归约的符号串的右端处于栈顶,语法分析器在栈中确定这个串的��左端非终结符来替换该串
- 接受:宣布语法分析过程成功完成
- 报错:发现一个语法错误,并调用错误恢复子程序

5.5 重要题型
-
前导知识:4种项目状态
- 归约项目:·在最后
- 接受项目:拓广文法的开始符号的产生式,且·在最后
- 移进项目:·后面是终结符
- 待约项目:·后面是非终结符
-
移入-归约分析
-
LR(0)分析表 / 构造其识别活前缀DFA
在写预测分析表的reduce项时,action的每一列都要写 -
SLR(1)分析表 / 构造其识别活前缀DFA
在写预测分析表的reduce项时,只写产生式左部的FOLLOW集对应的action列 -
LR(1)分析表 / 构造其识��别活前缀DFA
在构造项目集时,要加入前向搜索符;并且,在写预测分析表的reduce项时只写前向搜索符对应的action列 -
LALR(1)分析表 / 构造其识别活前缀DFA
在构造项目集时,要加入前向搜索符,但是要合并同心集,把相同表达式但是不同前向搜索符的前向搜索符合并,并且在写预测分析表的reduce项时只写前向搜索符集对应的action列
概念总结
1 编译程序各阶段功能
词法分析:从左到右扫描源程序,识别出各个单词,确定单词类型并形成单词序列,进行词法错误检查,对标识符进行登记,即符号表管理
语法分析:从词法分析输出的单词序列识别出各类短语,构造语法分析树,并进行语法错误检查
语义分析:审查程序是否具有语义错误,为代码生成阶段收集类型信息,不符合规��范时报错(符号表是语义正确性检查的依据)
中间代码生成:生成中间代码,如三地址指令、四元式、波兰式、逆波兰式、树形结构等
代码优化:对代码进行等价变换以求提高执行效率,提高速度或节省空间
目标代码生成:将中间代码转化成目标机上的机器指令代码或汇编代码(符号表是对符号分配地址的依据)
2 语法分析方法的概念
就产生语法树的方向而言,可大致分为自顶向下的语法分析和自底向上的语法分析两大类。
自顶向下的语法分析方法:主流方法为递归下降分析法。根据当前的输入符号唯一地确定选用哪个产生式替换相应的非终结符以往下推导。
自底向上的语法分析方法:将输入串w归约为文法开始符号S的过程。
LR(0), SLR(1), LR(1)
LR(0)文法可能存在移�进-归约冲突、归约-归约冲突
SLR(1)文法在构造的过程中不存在归约-归约冲突,但有可能出现移进-归约冲突,可以由FOLLOW集解决的话则是SLR(1)文法
3 翻译模式
翻译模式是适合语法制导语义计算的另一种描述形式,可以体现一种合理调用语义动作的算法。
-
S-翻译模式:
仅涉及综合属性的翻译模式,通常将语义动作集合置于产生式右端末尾。
-
L-翻译模式:
既可以包含综合属性,也可以包含继承属性。
4 属性文法
在文法基础上,为文法符号关联有特定意义的属性,并为产生式关联相应的语义动作,称之为属性文法。
-
S-属性文法:
只包含综合属性的属性文法成为S-属性文法
-
L-属性文法:
可以包含综合属性,也可以包含继承属性,但要求产生式右部的文法符号的继承属性的计算只取决于该符号左边符号的属性
5 符号表
符号表是编译程序中用于收集标识符的属性信息的数据结构。
各阶段作用:
- 语义分析阶段:语义合法性检查的依据
- 目标代码生成阶段:对符号名进行地址分配的依据