简历面试准备
一、U-2-Net
(一)SOD任务
显著性目标检测Salient Object Detection,相当于语义分割中的二分类任务,只有前景和背景
(二)网络结构
下图为U-2-Net的整体结构
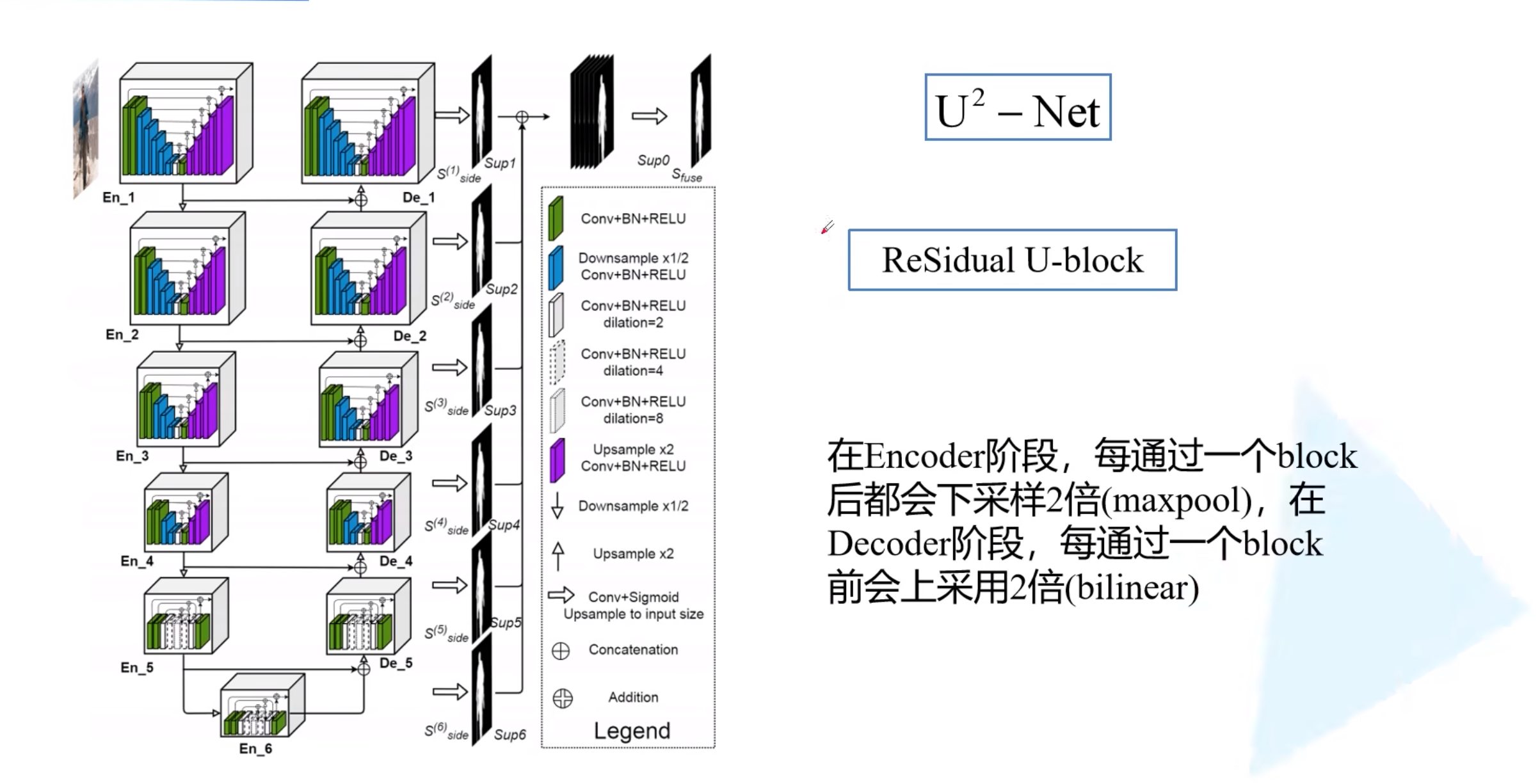
residual [rɪˈzɪdjuəl]
在encoder阶段,每个block之后使用maxpooling下采样两倍 在decoder阶段,每个block之后使用双线性插值上采样两倍
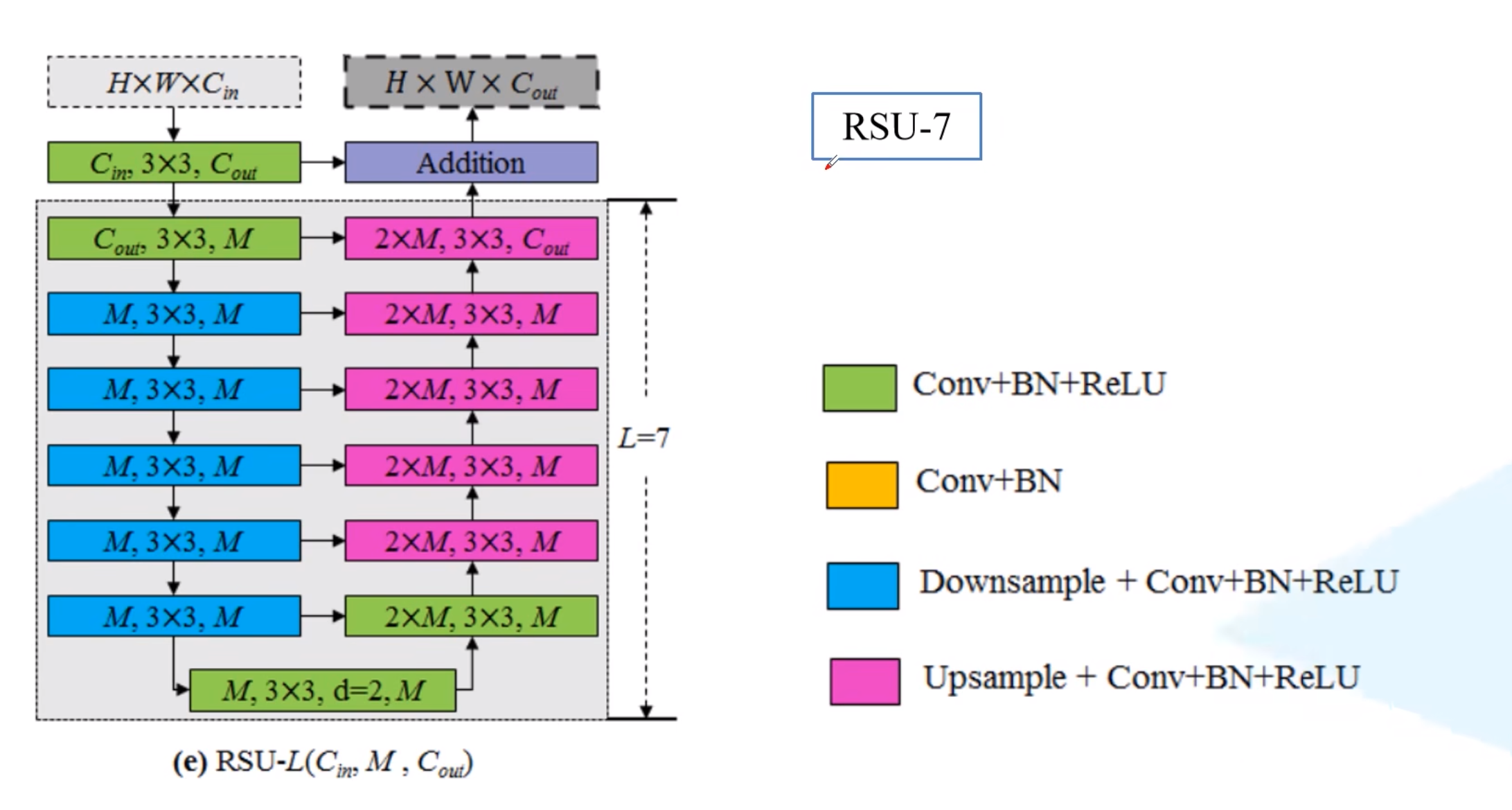
下图为Residual U-block的结构
在特征融合阶段,每一层的encoder-decoder输出,使用3x3卷积以及双线性插值上采样到原始分辨率得到该层的特征图,且卷积核的个数为1,输出的feature map通道数也为1。将每一层的feature map进行concat拼接,得到6通道的融合feature map,最后使用1x1卷积以及sigmoid激活函数得到最终的融合特征图输出
(三)损失函数
损失函数是7个损失项的加权求和 共有6层encoder-decoder结构,将每一层对应的feature map与ground truth做BCE Loss得到6个损失项 第7个损失项是最终融合得到的feature map与ground truth的BCE Loss 在论文中,每个损失项的权重都为1
canny边缘检测:
- 使用高斯滤波进行平滑
- 计算像素梯度
- 非极大值抑制
- 双阈值检测强边缘、弱边缘
- 边缘连接
(四)深度可分离卷积
深度可分离卷积的优点是可以在大致保持卷积效果的情况下减少参数量
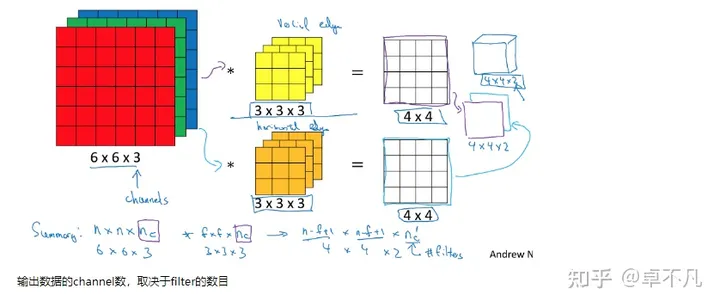
在实现原理上可分为两个步骤:深度卷积(depth wise)以及逐点(point wise)卷积
深度卷积是一种在每个输入通道上分别进行卷积操作的卷积方法,每个输入通道只与对应的卷积核进行卷积。
逐点卷积通过使用卷积对深度卷积的结果再次卷积
二、YOLO
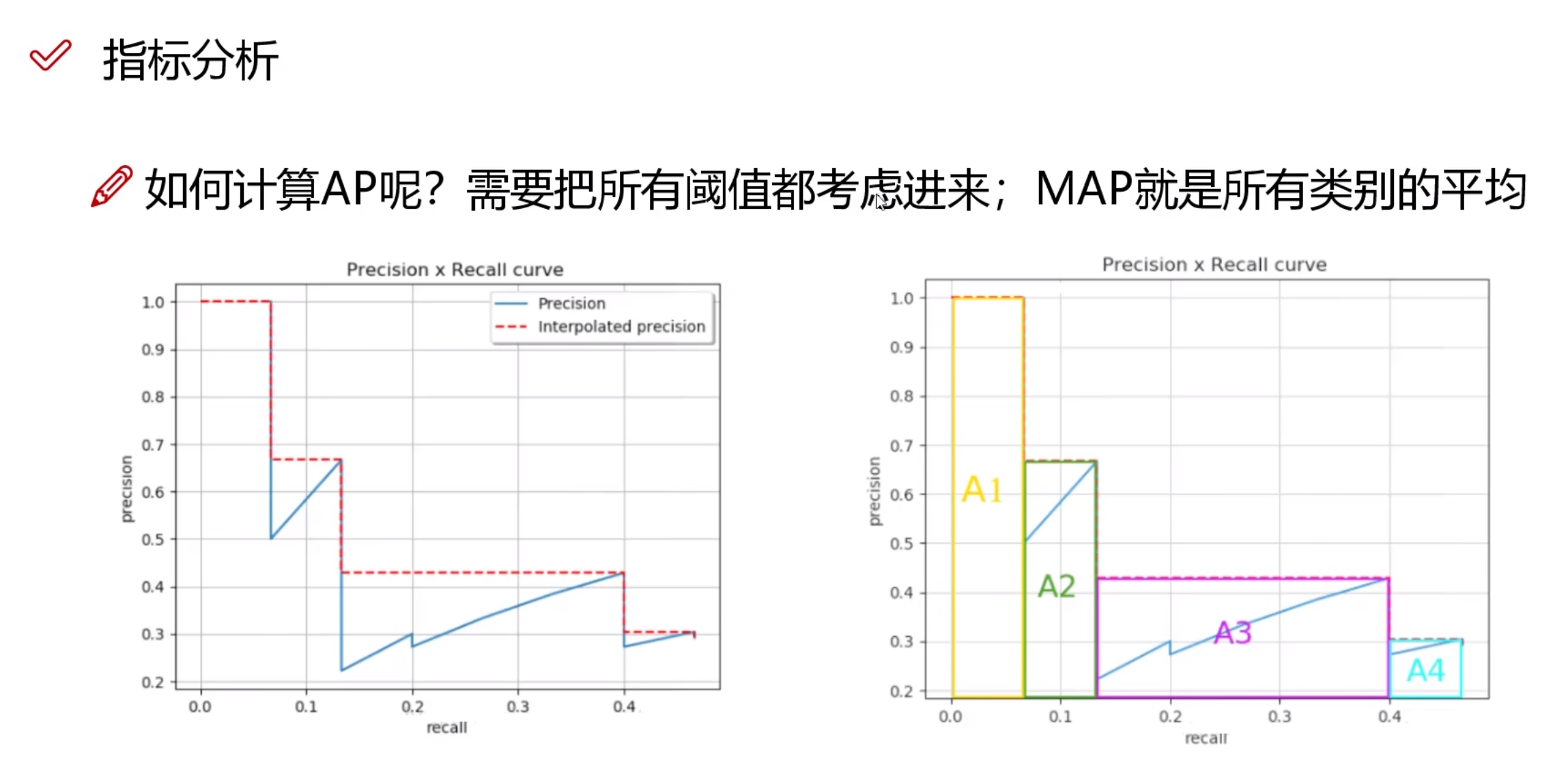
(一)mAP
PR曲线所围成的面积即使该类的AP值
(二)YOLOv1
1.预测阶段
下图为YOLOv1的算法框架
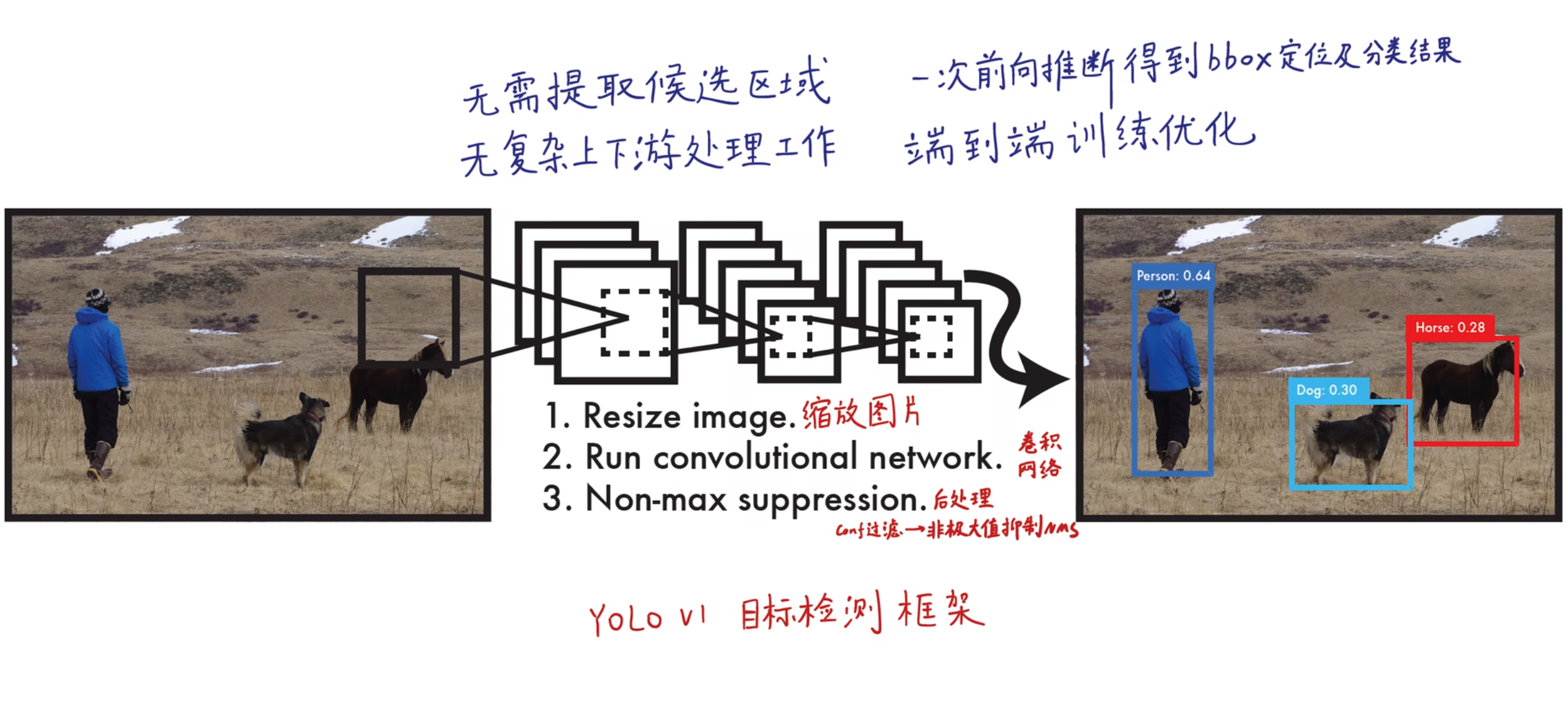
下图为YOLOv1的网络结构
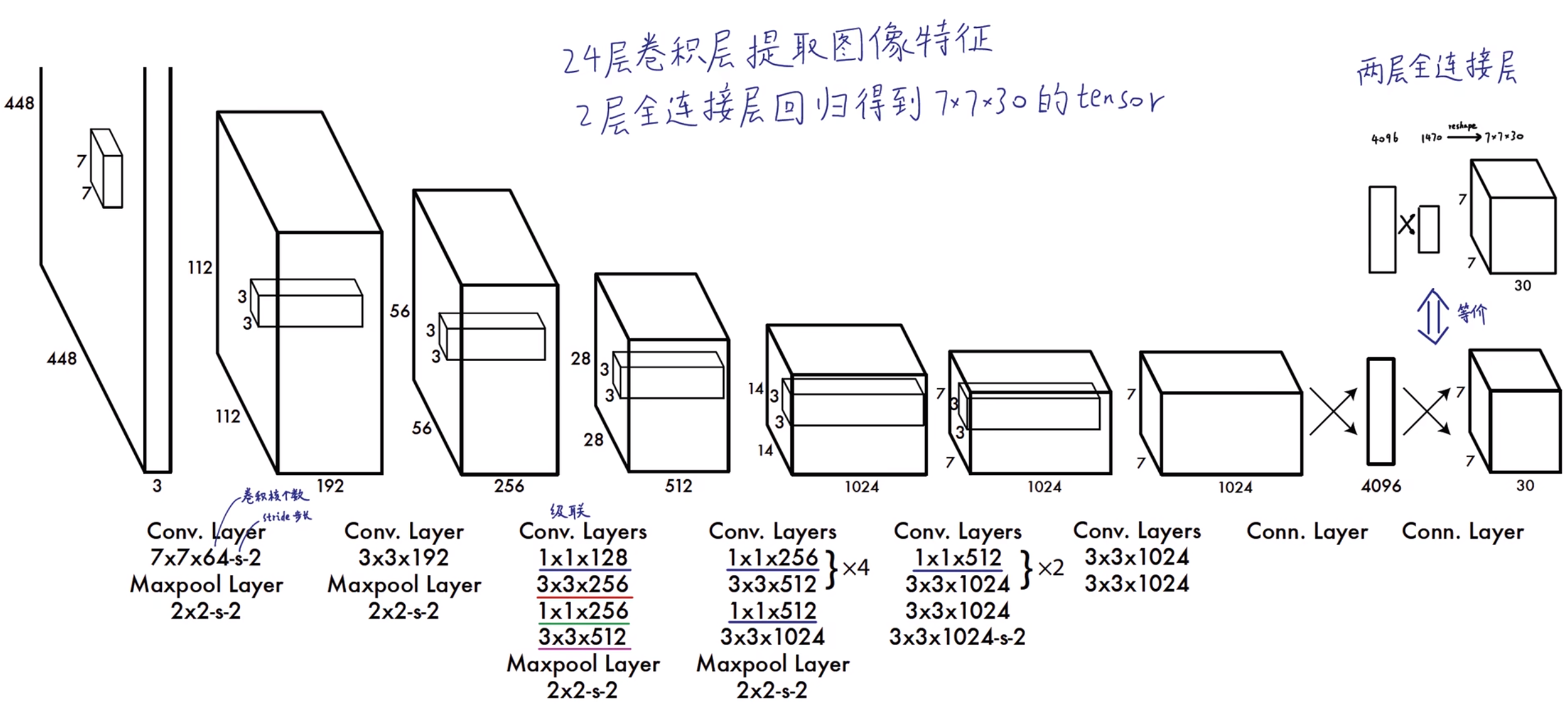
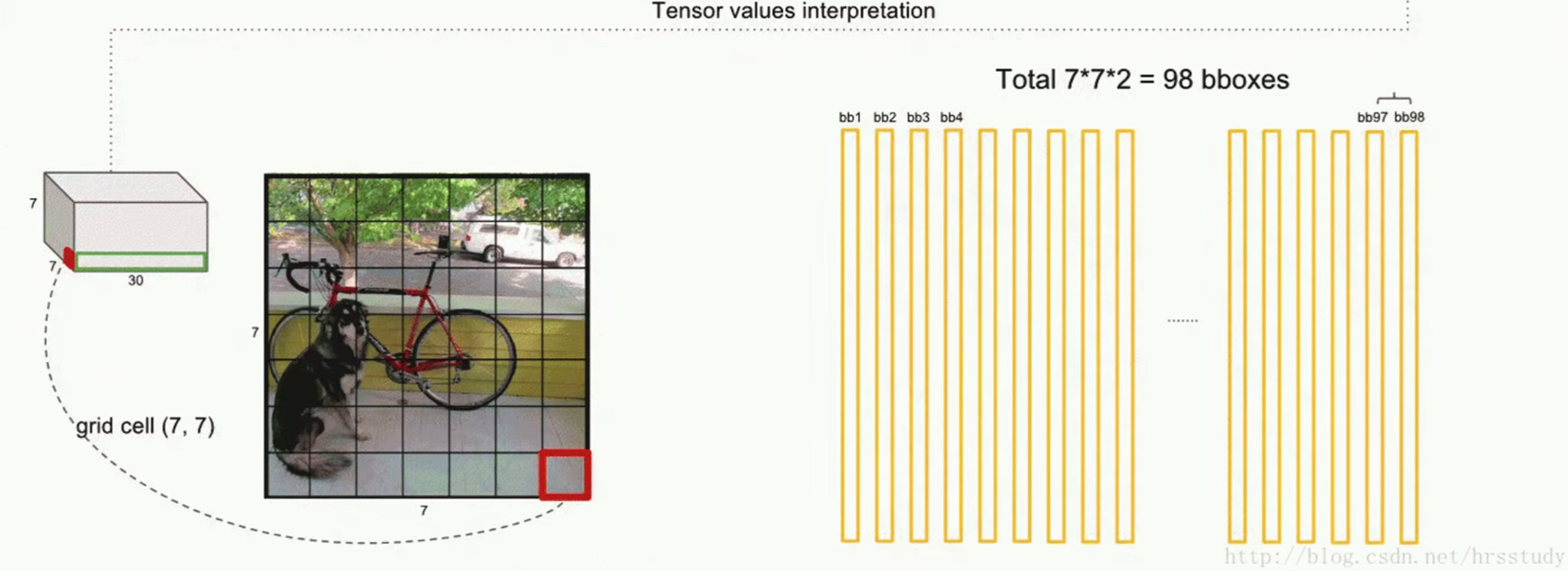
输入[448, 448, 3]图像,输出[7, 7, 30]的tensor(包含所有预测框的坐标、置信度和类别结果),通过解析输出的tensor得到�预测结果
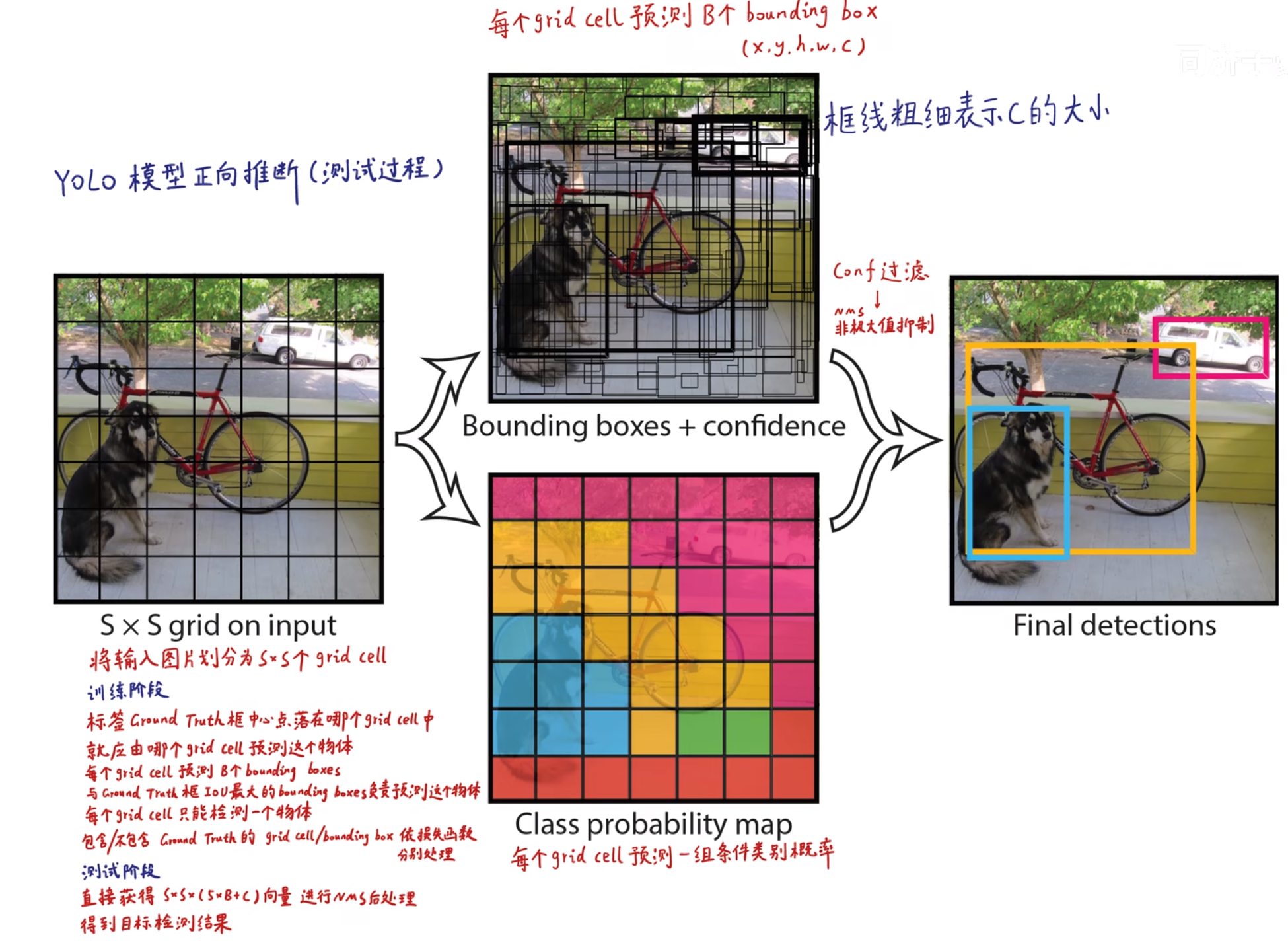
首先将输入图片划分为个grid cell。在YOLOv1中
每个grid cell预测出个bounding box预测框(bbox),每个bbox的中心点都落在该grid cell中。在YOLOv1中
每个bbox包含(x, y, h, w, c)五种信息,其中x, y为bbox左上角坐标,h, w为bbox的宽高,c为该bbox是否存在object的概率
同时每个grid cell预测出一组与数据集有关的条件类别概率。在YOLOv1论文使用的数据集Pascal VOC中,类别种类为20类,因此在预测阶段输出的[7, 7, 30]的tensor含义如下图所示
每个grid cell选出条件类别概率最大的类别,因此每个grid cell只能检测一个物体
这也是YOLOv1小目标和密集目标识别能力差的原因

每个bbox的置信度与其父grid cell的类别概率相乘得到全概率,如下图所示
进行NMS后处理:
- 对某一特定类别,首先根据全概率置信度排序
- 将此时最大置信度的bbox与其他所有置信度更小的bbox做IoU判断,若IoU大于设置的阈值,则抹除置信度小的bbox
- 将剩余的次大的置信度重复步骤2,抹除所有置信度更小的其IoU超过阈值的bbox
非极大值抑制只在预测阶段进行
在训练阶段,所有bbox都会在Loss Function中起到更新的作用,因此不进行NMS
2. 训练过程的损失函数
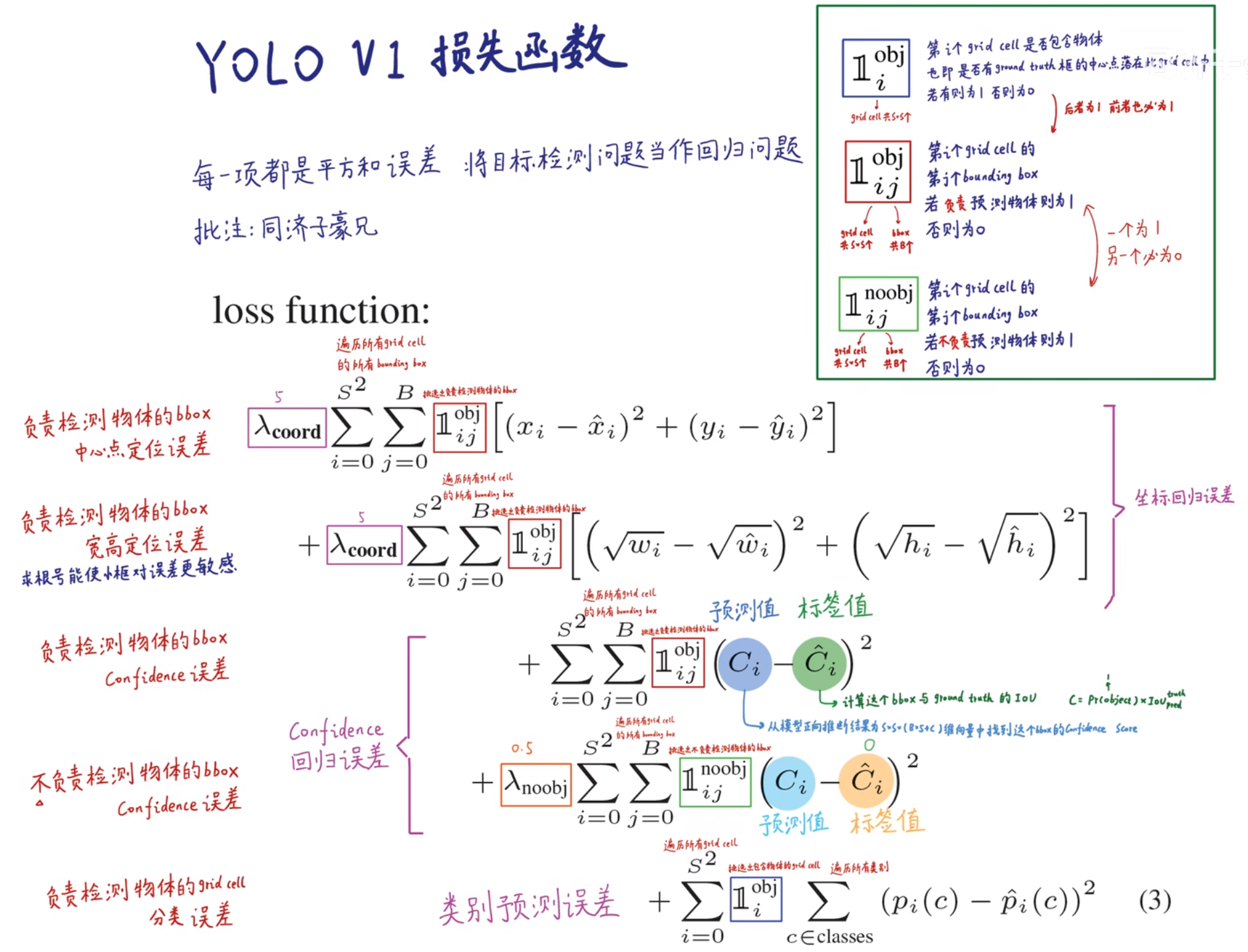
(二)YOLOv2
1. BN层

2. 高分辨率训练
3. Anchor
YOLOv2引入了anchor机制代替bbox,将图像划分为个grid cell,每个grid cell生成5个anchor
anchor是通过k-means聚类在数据集上生成的不同尺寸的先验框 对数据集进行anchor宽高比的聚类,聚类数越大,覆盖的IoU越大,但同时模型也更复杂
(三)YOLOv5
1. 特征融合
YOLOv5使用CSPNet实现特征融合,CSP模块由主干和分支构成,主干提取低维特征,分支提取高维特征
主干通过卷积和池化提取特征,形成不同尺寸的特征图
分支将主干输出的特征图作为输入,逐步卷积和上采样提取高级别语义特征
主干特征图通过卷积对通道数降维之后与分支在通道维度上concat
在特征提取以及融合阶段可以加入Canny边缘检测得到的特征图进行特征融合
2. 前处理
对填充黑色像素进行了改善,以填充更少的黑像素,提高了精度
3. 特征金字塔FCN
三、CBAM
CBAM是通道+空间注意力机制(SENet是通道注意力机制)
(一)总体结构
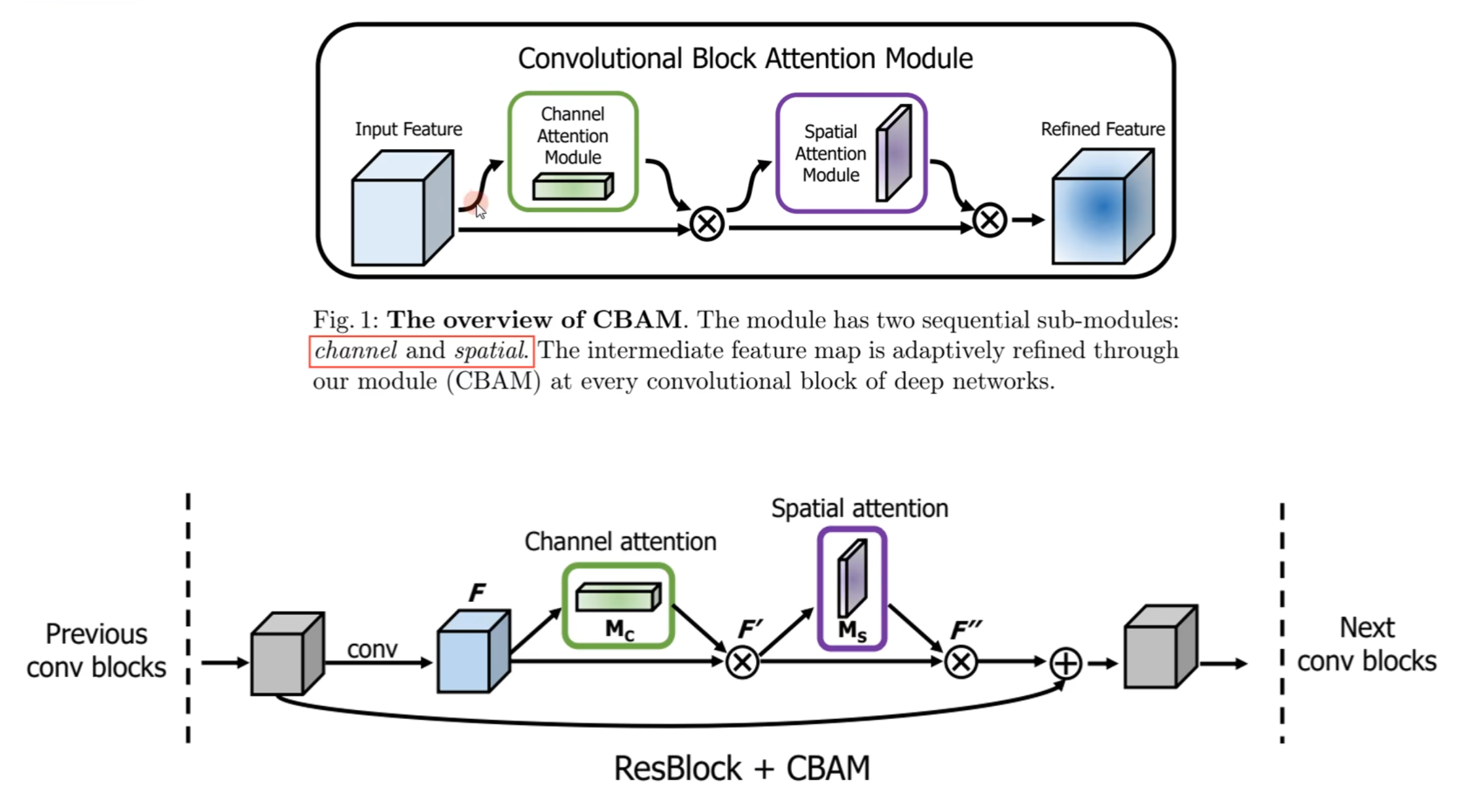
通道注意力:原始特征图经过通道注意力机制算法得到的tensor,代表不同通道之间的重要程度,将其与原始特征图相乘
空间注意力:经过通道注意力的特征图经过空间注意力机制算法得到的tensor,代表宽高维度的像素之间的重要程度,将其与原始特征图相乘
(二)通道注意力
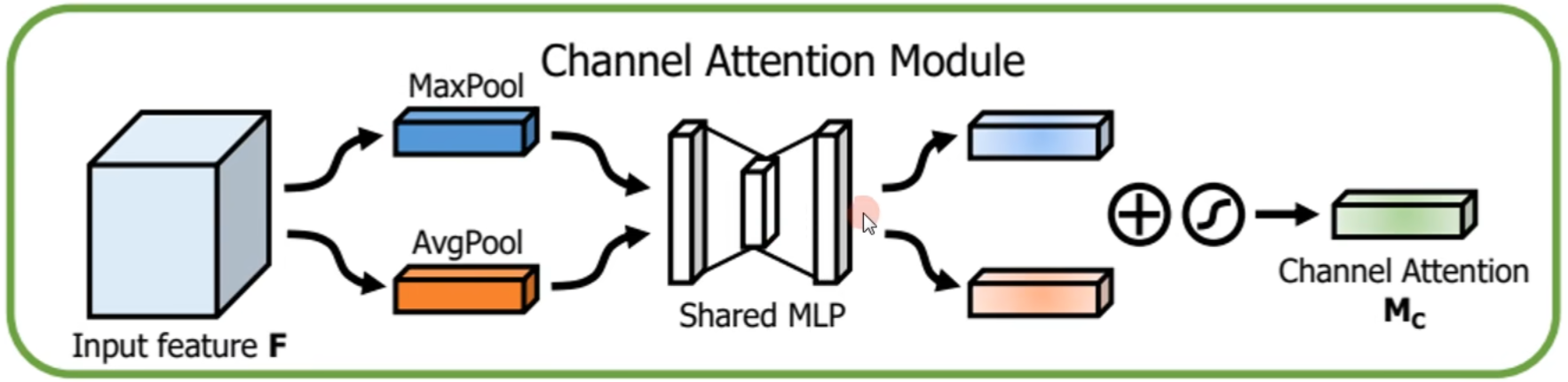
原始特征图分别经过最大池化和平均池化来压缩空间维度、学习通道之间的特征,得到的tensor,再送入共享的多层感知机网络进行降维再升维,最后将二者相加再经过sigmoid函数产生最终的通道注意力特征图
(三)空间注意力
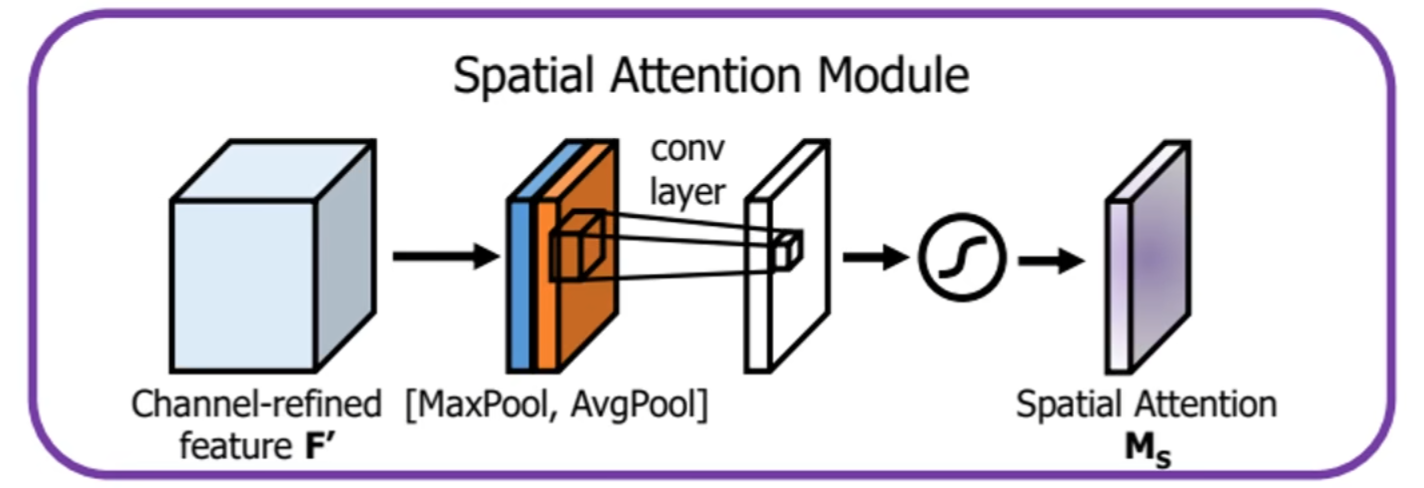
原始特征图分别经过最大池化和平均池化(通过torch.max和torch.mean函数实现)得到的tensor,再将二者concat后通过卷积学习特征并降维,最后送入sigmoid函数得到最终的空间注意力特征图
(四)其他注意事项
- 作者分别对通道注意力以及空间注意力使用最大池化还是平均池化做了消融实验,结果反映二者都用最大池化以及平均池化再相加效果最好(且对于卷积与卷积的消融实验发现,卷积效果更好)
- 作者对先通道注意力还是先空间注意力做了消融实验,结果发现先通道再空间效果更好
四、Focal Loss
Focal Loss通过引入修正项和样本关注度超参数,增加困难样本的关注度,来解决类别不均衡问题。
YOLO损失函数分为分类损失以及回归损失,可以在分类损失中引入Focal Loss代替原来的交叉熵损失
五、SENet
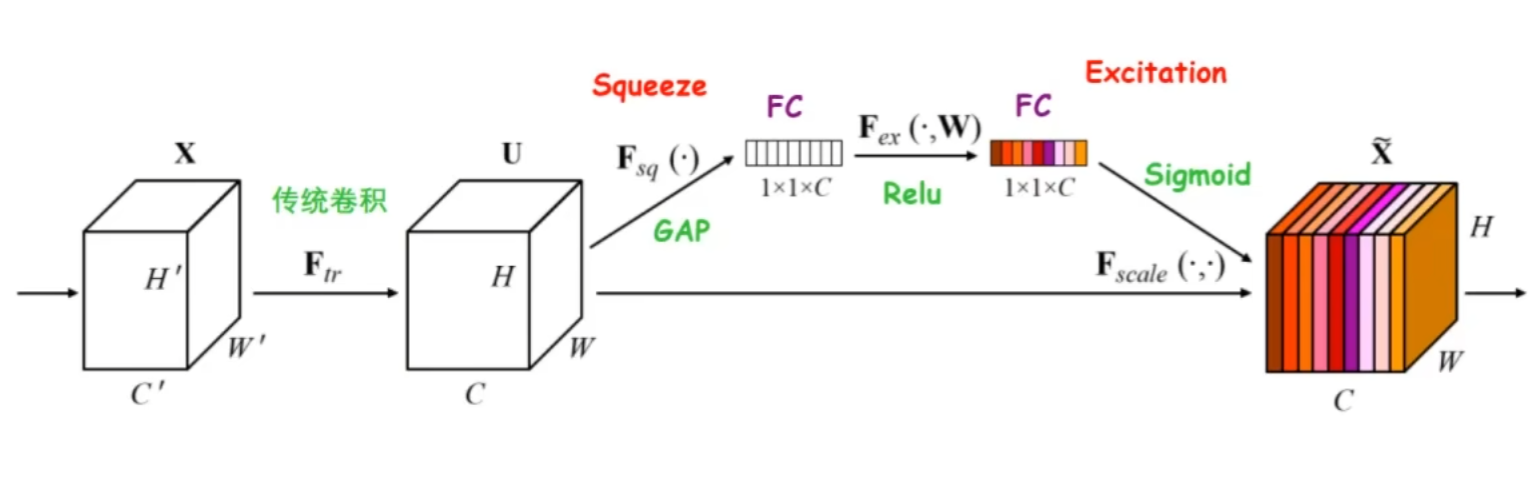
Squeeze and Excitation
Squeeze挤压操作就是将的特征图通过池化挤压宽高维度,得到的tensor,该tensor还要经过所示的全连接层-ReLU-全连接层结构
Excitation激励操作就是通过sigmoid函数得到每个通道之间的重要程度系数
六、自注意力机制
自注意力机制通过计算元素之间的相似度来确定它们之间的关联性,并对其进行加权处理以获得上下文信息。
- 自注意力机制通过对输入的元素进行线性变换来得到查询(Query)向量、键(Key)向量和值(Value)向量。
- 通过点积和缩放点积计算相似程度
通过自注意力机制,每个元素都可以通过与其他元素的相似度计算和加权求和,获取到与它们相关的上下文信息。相似度高的元素将获得更高的权重,因此更受到关注和影响,从而建立起元素之间的关联性。
七、自我介绍
(一)英文自我介绍
This content has been encrypted.
(二)西电广研院自我介绍
1. 英文自我介绍
This content has been encrypted.
2. 中文自我介绍
This content has been encrypted.
(三)电子科技大学自我介绍
1. 英文自我介绍
This content has been encrypted.
2. 中文自我介绍
This content has been encrypted.