主要技术简记
Llama 3
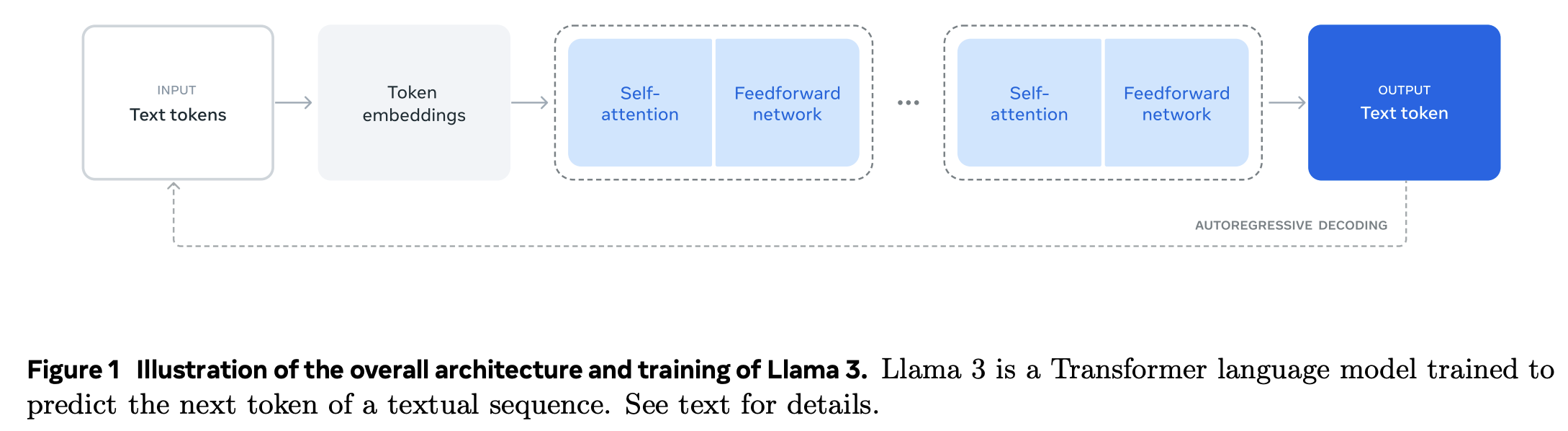
整体结构
自回归模型,与 GPT 相同预测下一个 token。
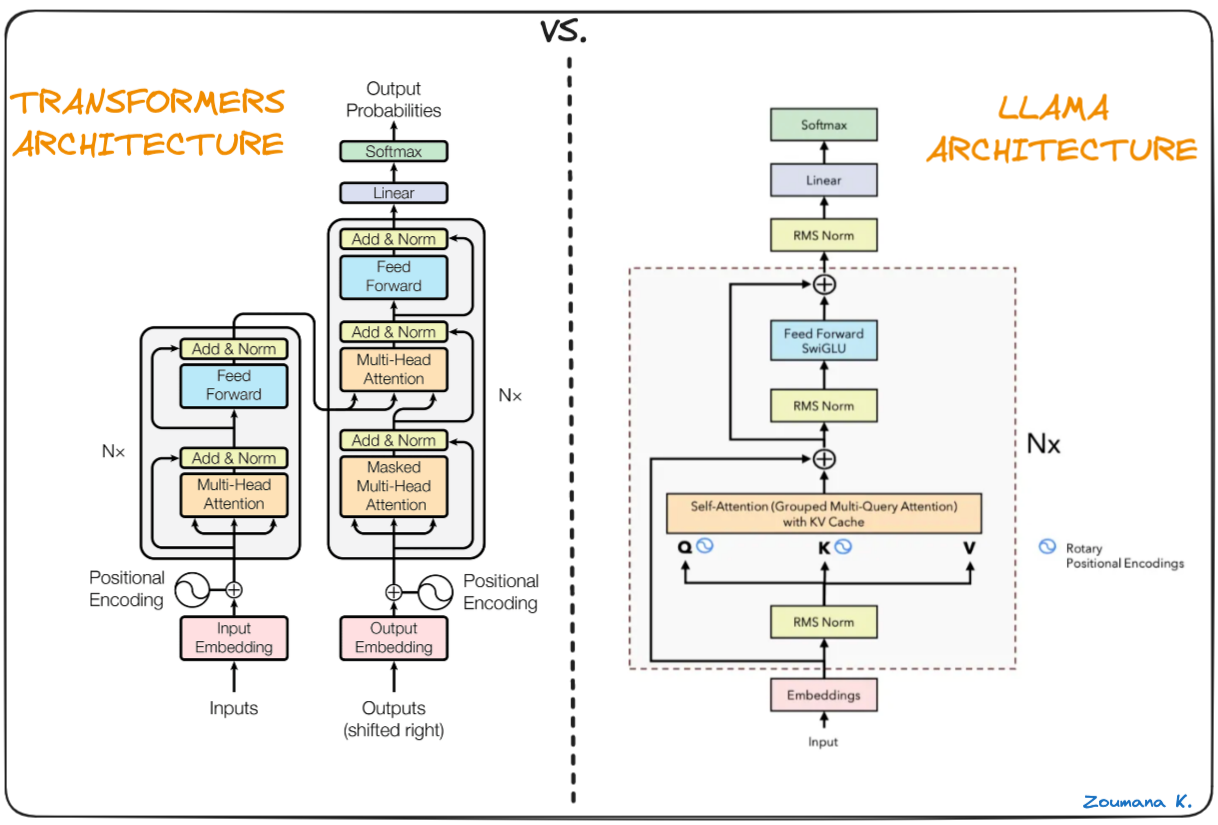
均方根层归一化(RMS Layer Normalization)

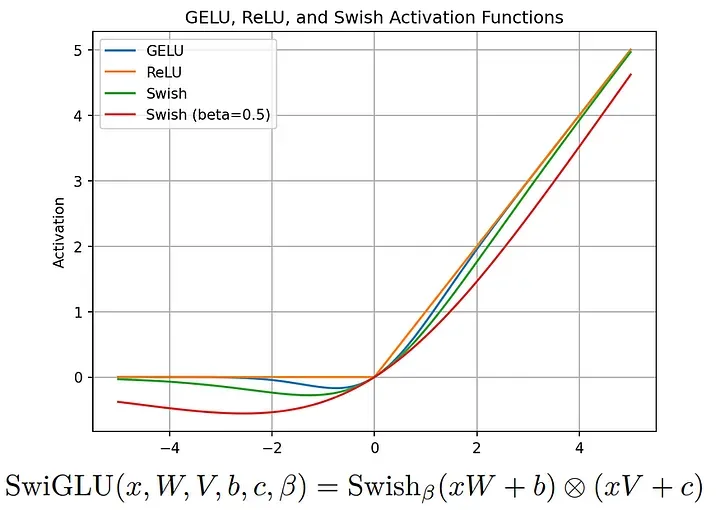
SwiGLU 激活函数
在生成文本之前,SwiGLU 会根据每个单词(word)或短语(phrase)与上下文的相关性(relevance)调整其重要性(importance)。
旋转位置编码(Rotary Positional Embedding)
旋转编码(Rotary Embeddings),简称 RoPE ,是 LLaMA 3 中采用的一种位置编码方式(position embedding)。
因此,在处理文本的过程中,RoPE 并未简单地将位置编码视作固定、静态的(fixed and static)元素,而是巧妙地融入了旋转(rotational)这一概念,使得表示方式更加灵活、多样化,能够更精准地把握文本序列内词语间的变化关系。这种灵活性赋予了 ChatGPT 等模型更强的能力,使其能更深刻地理解和生成自然流畅、逻辑连贯的文本内容,就如同在教室中采用动态座位布局(dynamic seating arrangement)能够激发更多互动式的讨论一样。
新的字节对编码(Tiktoken BPE)
LLaMA 3 采用由 OpenAI 推出的 tiktoken 库中的字节对编码(Byte Pair Encoding, BPE),而 LLaMA 2 的 BPE 分词机制基于 sentencepiece 库。两者虽有微妙差异,但目前的首要任务是理解 BPE 究竟是什么。
先从一个简单的例子开始:假设有一个文本语料库(text corpus),内含 "ab", "bc", "bcd", 和 "cde" 这些词语。我们将语料库中所有单词拆分为单个字符纳入词汇表,此时的词汇表为 {"a", "b", "c", "d", "e"}。
接下来,计算各字符在文本语料库中的出现次数。在本例中,统计结果为 {"a": 1, "b": 3, "c": 3, "d": 2, "e": 1}。
- 随后,进入核心环节 ------ 合并阶段(merging process)。重复执行以下操作直至词汇表达到预定规模:第一步,找出频次最高的连续字符组合。 在本例中,频次最高的一对字符是 "bc",频次为 2。然后,我们将这对字符合并,生成新的子词单元(subword unit)"bc"。合并后,更新字符频次,更新后的频次为 {"a": 1, "b": 2, "c": 2, "d": 2, "e": 1, "bc": 2}。我们将新的子词单元 "bc" 加入词汇表,使之扩充至 {"a", "b", "c", "d", "e", "bc"}。
- 重复循环这一过程。 下一个出现频次最高的词对是 "cd",将其合并生成新的子词单元 "cd",并同步更新频次。更新后为 {"a": 1, "b": 2, "c": 1, "d": 1, "e": 1, "bc": 2, "cd": 2}。然后我们将 "cd" 加入词汇表,得到 {"a", "b", "c", "d", "e", "bc", "cd"}。
- 延续此流程,下一个频繁出现的词对是 "de",将其合并为子词单元 "de",并将频次更新至 {"a": 1, "b": 2, "c": 1, "d": 1, "e": 0, "bc": 2, "cd": 1, "de": 1}。然后将 "de" 添加到词汇表中,使其更新为 {"a", "b", "c", "d", "e", "bc", "cd", "de"}。
- 接下来,我们发现 "ab" 是出现频次最高的词对,将其合并为子词单元 "ab",同步更新频次为 {"a": 0, "b": 1, "c": 1, "d": 1, "e": 0, "bc": 2, "cd": 1, "de": 1, "ab": 1}。再将 "ab" 添加至词汇表中,使其扩容至 {"a", "b", "c", "d", "e", "bc", "cd", "de", "ab"}。
- 再往后,"bcd" 成为了下一个出现频次最高的词对,将其合并为子词单元 "bcd",更新频次至 {"a": 0, "b": 0, "c": 0, "d": 0, "e": 0, "bc": 1, "cd": 0, "de": 1, "ab": 1, "bcd": 1}。将 "bcd" 添入词汇表,使其升级为 {"a", "b", "c", "d", "e", "bc", "cd", "de", "ab", "bcd"}。
- 最后,出现频次最高的词对是 "cde",将其合并为子词单元 "cde",更新频次至 {"a": 0, "b": 0, "c": 0, "d": 0, "e": 0, "bc": 1, "cd": 0, "de": 0, "ab": 1, "bcd": 1, "cde": 1}。将 "cde" 添加入词汇表,这样词汇表就变为了 {"a", "b", "c", "d", "e", "bc", "cd", "de", "ab", "bcd", "cde"}。
此方法能够显著提升大语言模型(LLMs)的性能,同时能够有效处理生僻词及词汇表之外的词汇。TikToken BPE 与 sentencepiece BPE 的主要区别在于:TikToken BPE 不会盲目将已知的完整词汇分割。 比如,若 "hugging" 已存在于词汇表中,它会保持原样,不会被拆解成 ["hug","ging"]。